 |
||||
|
← |
Д.А. Шабанов, М.А.Кравченко. Статистический анализ данных в зоологии и экологии |
→ |
||
|
Тема 9. Метод главных компонент |
||||
|
Биостатистика-12 |
Биостатистика-14 |
|||
9.1. Сущность метода (на двумерном примере)
Метод главных компонент или компонентный анализ (principal component analysis, PCA) — один из важнейших методов в арсенале зоолога или эколога. К сожалению, в тех случаях, когда вполне уместным является применение компонентного анализа, сплошь и рядом применяют кластерный анализ.
Типичная задача, для которой полезен компонентный анализ, такова: есть некое множество объектов, каждый из которых охарактеризован по определенному (достаточно большому) количеству признаков. Исследователя интересуют закономерности, отраженные в разнообразии этих объектов. В том случае, когда есть основания предполагать, что объекты распределены по иерархически соподчиненным группам, можно использовать кластерный анализ — метод классификации (распределения по группам). Если нет оснований ожидать, что в разнообразии объектов отражена какая-то иерархия, логично использовать ординацию (упорядоченное расположение). Если каждый объект охарактеризован по достаточно большому количеству признаков (по крайней мере — такому количеству признаков, какое не получается адекватно отразить на одном графике), оптимально начинать исследование данных с анализа главных компонент. Дело в том, что этот метод является одновременно методом понижения размерности (количества измерений) данных.
Если группа рассматриваемых объектов охарактеризована значениями одного признака, для характеристики их разнообразия можно использовать гистограмму (для непрерывных признаков) или столбчатую диаграмму (для характеристики частот дискретного признака). Если объекты охарактеризованы двумя признаками, можно использовать двумерный график рассеяния, если тремя — трехмерный. А если признаков много? Можно попытаться на двумерном графике отразить взаимное расположение объектов друг относительно друга в многомерном пространстве. Обычно такое понижение размерности связано с потерей информации. Из разных возможных способов такого отображения надо выбрать тот, при котором потеря информации будет минимальной.
Поясним сказанное на самом простом примере: переходе от двумерного пространства к одномерному. Минимальное количество точек, которое задает двумерное пространство (плоскость) — 3. На рис. 9.1.1 показано расположение трех точек на плоскости. Координаты этих точек легко читаются по самому рисунку. Как выбрать прямую, которая будет нести максимальную информацию о взаиморасположении точек?
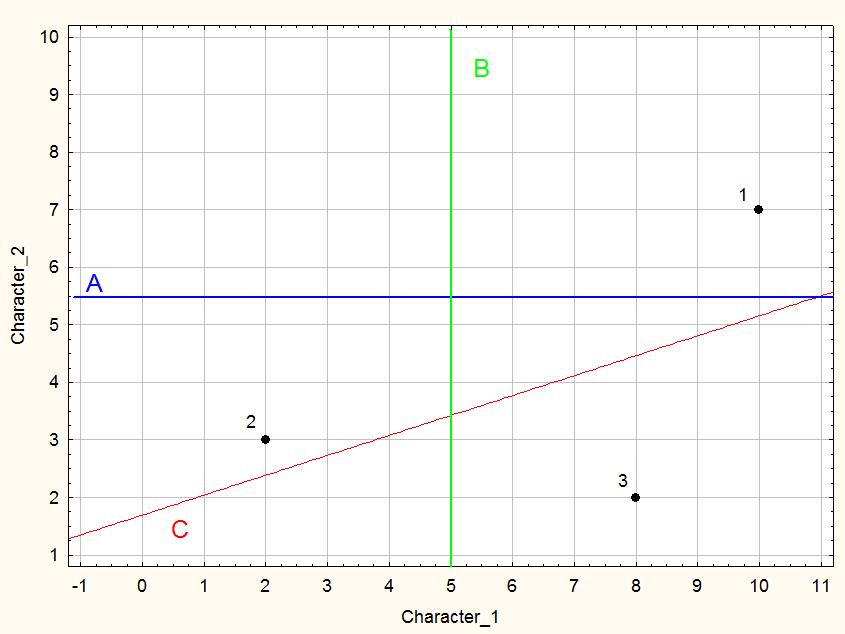
Рис. 9.1.1. Три точки на плоскости, заданной двумя признаками. На какую прямую будет проецироваться максимальная дисперсия этих точек?
Рассмотрим проекции точек на прямую A (показанную синим цветом). Координаты проекций этих точек на прямую A таковы: 2, 8, 10. Среднее значение — 62/3. Дисперсия (2-62/3)+ (8-62/3)+ (10-62/3)=342/3.
Теперь рассмотрим прямую B (показанную зеленым цветом). Координаты точек — 2, 3, 7; среднее значение — 4, дисперсия — 14. Таким образом, на прямую B отражается меньшая доля дисперсии, чем на прямую A.
Какова эта доля? Поскольку прямые A и B ортогональны (перпендикулярны), доли общей дисперсии, проецирующиеся на A и B, не пересекаются. Значит, общую дисперсию расположения интересующих нас точек можно вычислить как сумму этих двух слагаемых: 342/3+14=482/3. При этом на прямую A проецируется 71,2% общей дисперсии, а на прямую B — 28,8%.
А как определить, на какую прямую отразится максимальная доля дисперсии? Эта прямая будет соответствовать линии регрессии для интересующих нас точек, которая обозначена как C (красный цвет). На эту прямую отразится 77,2% общей дисперсии, и это — максимально возможное значение при данном расположении точек. Такую прямую, на которую проецируется максимальная доля общей дисперсии, называют первой главной компонентой.
А на какую прямую отразить оставшиеся 22,8% общей дисперсии? На прямую, перпендикулярную первой главной компоненте. Эта прямая тоже будет являться главной компонентой, ведь на нее отразится максимально возможная доля дисперсии (естественно, без учета той, которая отразилась на первую главную компоненту). Таким образом, это — вторая главная компонента.
Вычислив эти главные компоненты с помощью Statistica (диалог мы опишем чуть позже), мы получим картину, показанную на рис. 9.1.2. Координаты точек на главных компонентах показываются в стандартных отклонениях.
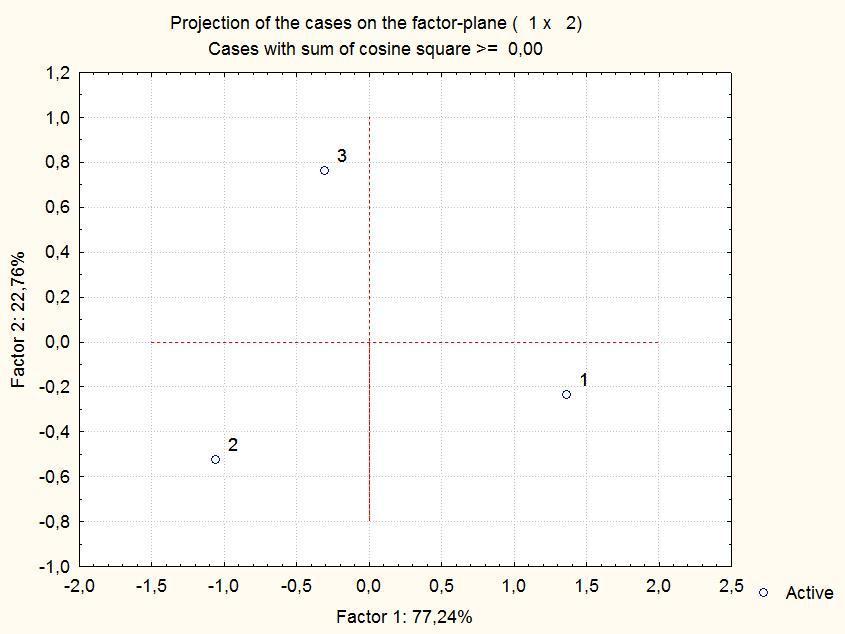
Рис. 9.1.2. Расположение трех точек, показанных на рис. 9.1.1, на плоскости двух главных компонент. Почему эти точки располагаются друг относительно друга иначе, чем на рис. 9.1.1?
На рис. 9.1.2 взаиморасположение точек оказывается измененным. Чтобы в дальнейшем правильно интерпретировать подобные картинки, следует рассмотреть причины отличий в расположении точек на рис. 9.1.1 и 9.1.2 подробнее. Точка 1 в обоих случаях находится правее (имеет большую координату по первому признаку и первой главной компоненте), чем точка 2. Но, почему-то, точка 3 на исходном расположении находится ниже двух других точек (имеет наименьшее значение признака 2), и выше двух других точек на плоскости главных компонент (имеет большую координату по второй компоненте). Это связано с тем, что метод главных компонент оптимизирует именно дисперсию исходных данных, проецирующихся на выбираемые им оси. Если главная компонента коррелирована с какой-то исходной осью, компонента и ось могут быть направлены в одну сторону (иметь положительную корреляцию) или в противоположные стороны (иметь отрицательные корреляции). Оба эти варианта равнозначны. Алгоритм метода главных компонент может «перевернуть» или не «перевернуть» любую плоскость; никаких выводов на основании этого делать не следует.
Однако точки на рис. 9.1.2 не просто «перевернуты» по сравнению с их взаиморасположением на рис. 9.1.1; определенным образом изменилось и их взаиморасположения. Отличия между точками по второй главной компоненте кажутся усиленными. 22,76% общей дисперсии, приходящиеся на вторую компоненту, «раздвинули» точки на такую же дистанцию, как и 77,24% дисперсии, приходящихся на первую главную компоненту.
Чтобы расположение точек на плоскости главных компонент соответствовало их действительному расположению, эту плоскость следовало бы исказить. На рис. 9.1.3. показаны два концентрических круга; их радиусы соотносятся как доли дисперсий, отражаемых первой и второй главными компонентами. Картинка, соответствующая рис. 9.1.2, искажена так, чтобы среднеквадратичное отклонение по первой главной компоненте соответствовало большему кругу, а по второй — меньшему.
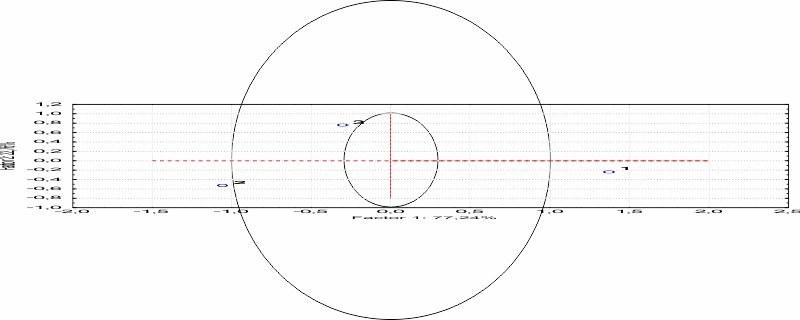
Рис. 9.1.3. Мы учли, что на первую главную компоненту приходится большая доля дисперсии, чем на вторую. Для этого мы исказили рис. 9.1.2, подогнав его под два концентрических круга, радиусы которых соотносятся, как доли дисперсий, приходящихся на главные компоненты. Но расположение точек все равно не соответствует исходному, показанному на рис. 9.1.1!
А почему взаимное расположение точек на рис. 9.1.3 не соответствует таковому на рис. 9.1.1? На исходном рисунке, рис. 9.1 точки расположены в соответствии со своими координатами, а не в соответствии с долями дисперсии, приходящимися на каждую ось. Расстоянию в 1 единицу по первому признаку (по оси абсцисс) на рис. 9.1.1 приходятся меньшая доля дисперсии точек по этой оси, чем расстоянию в 1 единицу по второму признаку (по оси ординат). А на рис 9.1.1 расстояния между точками определяются именно теми единицами, в которых измеряются признаки, по которым они описаны.
Несколько усложним задачу. В табл. 9.1.1 показаны координаты 10 точек в 10-мерном пространстве. Первые три точки и первые два измерения — это тот пример, который мы только что рассматривали.
Таблица 9.1.1. Координаты точек для дальнейшего анализа
|
Точки |
Координаты |
|||||||||
|
Character 1 |
Character 2 |
Character 3 |
Character 4 |
Character 5 |
Character 6 |
Character 7 |
Character 8 |
Character 9 |
Character 10 |
|
|
1 |
10 |
7 |
6 |
9 |
5 |
8 |
6 |
1 |
9 |
7 |
|
2 |
2 |
3 |
2 |
1 |
7 |
1 |
8 |
5 |
7 |
1 |
|
3 |
8 |
2 |
3 |
6 |
9 |
2 |
2 |
1 |
5 |
8 |
|
4 |
2 |
7 |
4 |
1 |
5 |
3 |
9 |
8 |
3 |
2 |
|
5 |
8 |
6 |
5 |
1 |
6 |
4 |
3 |
9 |
2 |
7 |
|
6 |
8 |
10 |
7 |
8 |
2 |
1 |
3 |
5 |
2 |
4 |
|
7 |
2 |
5 |
3 |
5 |
5 |
6 |
9 |
9 |
2 |
1 |
|
8 |
6 |
3 |
3 |
6 |
7 |
8 |
2 |
4 |
1 |
8 |
|
9 |
6 |
1 |
2 |
4 |
9 |
6 |
1 |
3 |
7 |
3 |
|
10 |
4 |
4 |
3 |
7 |
8 |
2 |
1 |
7 |
5 |
8 |
В учебных целях вначале рассмотрим только часть данных из табл. 9.1.1. На рис. 9.1.4 мы видим положение десяти точек на плоскости первых двух признаков. Обратите внимание, что первая главная компонента (прямая C) прошла несколько иначе, чем в предыдущем случае. Ничего удивительного: на ее положение влияют все рассматриваемые точки.
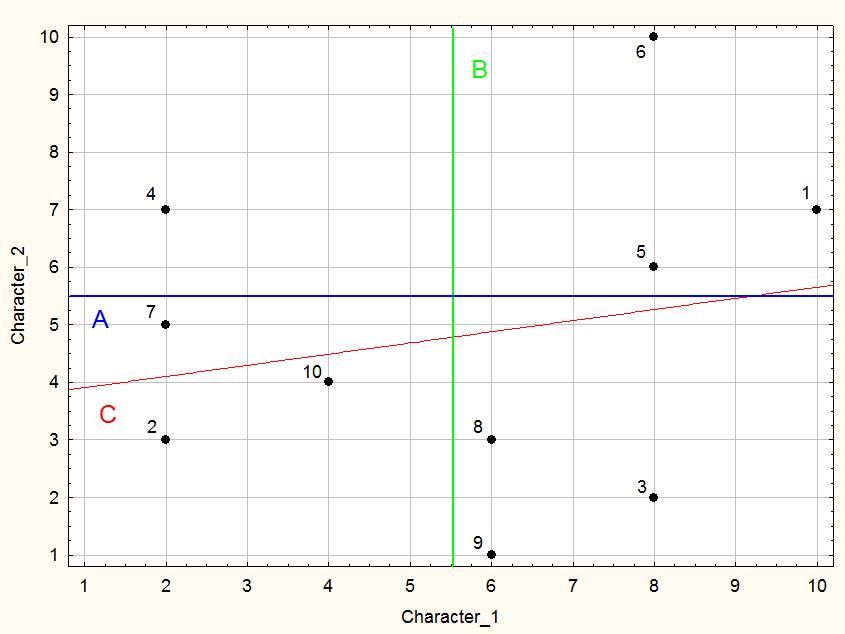
Рис. 9.1.4. Мы увеличили количество точек. Первая главная компонента проходит уже несколько иначе, ведь на нее оказали влияние добавленные точки
На рис. 9.1.5 показано положение рассмотренных нами 10 точек на плоскости двух первых компонент. Обратите внимание: все изменилось, не только доля дисперсии, приходящейся на каждую главную компоненту, но даже положение первых трех точек!
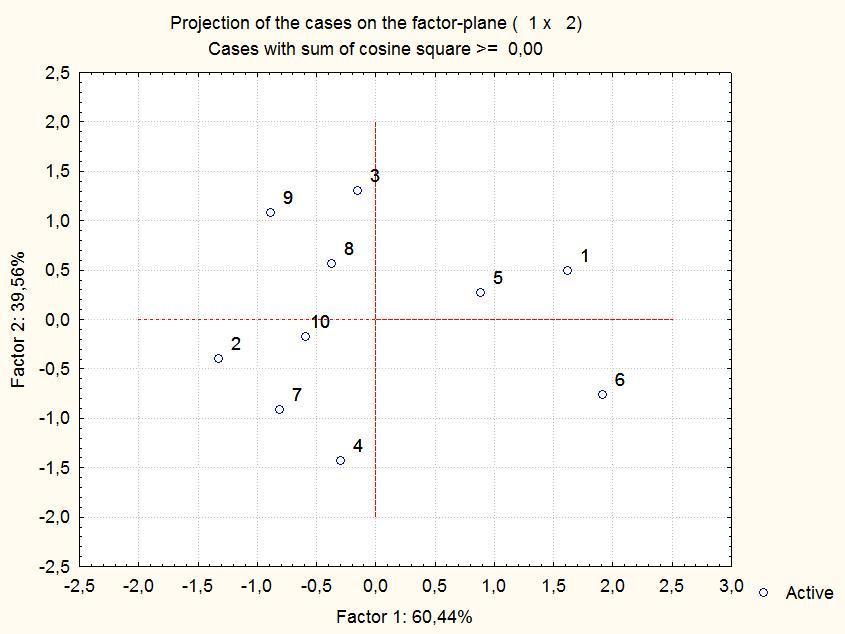
Рис. 9.1.5. Ординация в плоскости первых главных компонент 10 точек, охарактеризованных в табл. 9.1.1. Рассматривались только значения двух первых признаков, последние 8 столбцов табл. 9.1.1 не использовались
В общем, это естественно: раз главные компоненты расположены иначе, то изменилось и взаиморасположение точек.
Трудности в сопоставлении расположения точек на плоскости главных компонент и на исходной плоскости значений их признаков могут вызвать недоумение: зачем использовать такой трудноинтерпретируемый метод? Ответ прост. В том случае, если сравниваемые объекты описаны всего по двум признакам, вполне можно использовать их ординацию по этим, исходным признакам. Все преимущества метода главных компонент проявляются в случае многомерных данных. Метод главных компонент в таком случае оказывается эффективным способом снижения размерности данных.
9.2. Переход к начальным данным с большим количеством измерений
Рассмотрим более сложный случай: проанализируем данные, представленные в табл. 9.1.1 по всем десяти признакам. На рис. 9.2.1 показано, как вызывается окно интересующего нас метода.
Рис. 9.2.1. Запуск метода главных компонент
Нас будет интересовать только выбор признаков для анализа, хотя диалог Statistica позмоляет намного более тонкую настройку (рис. 9.2.2).
Рис. 9.2.2. Выбор переменных для анализа
После выполнения анализа появляется окно его результатов с несколькими вкладками (рис. 9.2.3). Все основные окна доступны уже из первой вкладки.
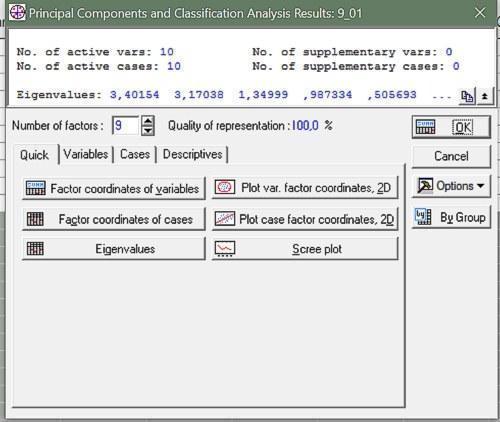
Рис. 9.2.3. Первая вкладка диалога результатов анализа главных компонент
Можно увидеть, что анализ выделил 9 главных компонент, причем описал с их помощью 100% дисперсии, отраженной в 10 начальных признаках. Это означает, что один признак был лишним, избыточным.
Начнем просматривать результаты с кнопки «Plot case factor voordinates, 2D»: она покажет расположение точек на плоскости, заданной двумя главными компонентами. Нажав эту кнопку, мы попадем в диалог, где надо будет указать, какие мы будем использовать компоненты; естественно начинать анализ с первой и второй компонент. Результат — на рис. 9.2.4.
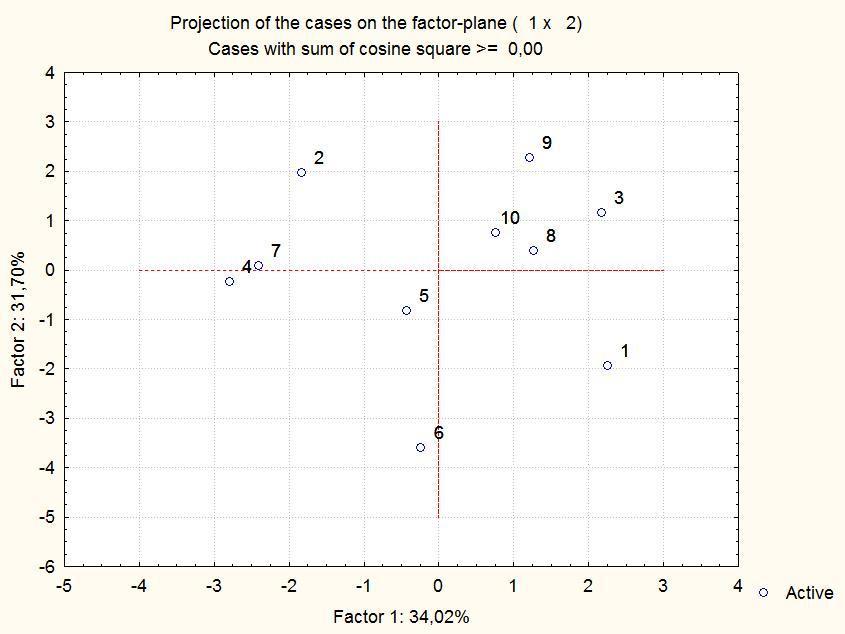
Рис. 9.2.4. Ординация рассматриваемых объектов на плоскости двух первых главных компонент
Положение точек изменилось, и это естественно: в анализ вовлечены новые признаки. На рис. 9.2.4 отражено более 65% всего разнообразия в положении точек друг относительно друга, и это уже нетривиальный результат. К примеру, вернувшись к табл. 9.1.1, можно убедиться в том, что точки 4 и 7, а также 8 и 10 действительно достаточно близки друг к другу. Впрочем, отличия между ними могут касаться других главных компонент, не показанных на рисунке: на них, все-таки, тоже приходится треть оставшейся изменчивости.
Кстати, при анализе размещения точек на плоскости главных компонент может возникнуть необходимость проанализировать расстояния между ними. Проще всего получить матрицу дистанций между точками с использованием модуля для кластерного анализа.
А как выделенные главные компоненты связаны с исходными признаками? Это можно узнать, нажав кнопку (рис. 9.2.3) Plot var. factor coordinates, 2D. Результат — на рис. 9.2.5.
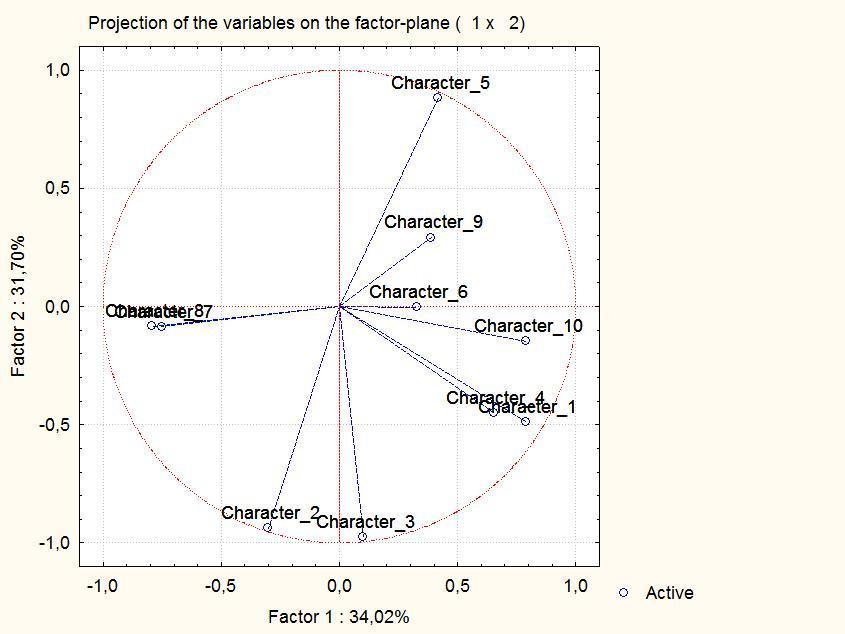
Рис. 9.2.5. Проекции исходных признаков на плоскость двух первых главных компонент
Мы смотрим на плоскость двух главных компонент «сверху». Исходные признаки, которые никак не связаны с главными компонентами, будет перпендикулярны (или почти перпендикулярны) им и отразятся короткими отрезками, заканчивающимися вблизи начала координат. Так, меньше всего с двумя первыми главными компонентами связан признак № 6 (хотя он демонстрирует определенную положительную корреляцию с первой компонентой). Отрезки, соответствующие тем признакам, которые полностью отразятся на плоскости главных компонент, будут заканчиваться на охватывающей центр рисунка окружности единичного радиуса.
Например, можно увидеть, что на первую главную компоненту сильнее всего повлияли признаки 10 (связан положительной корреляцией), а также 7 и 8 (связаны отрицательной корреляцией). Чтобы рассмотреть структуру таких корреляций подробнее, можно нажать кнопку Factor coordinates of variables, и получить таблицу, показанную на рис. 9.2.6.
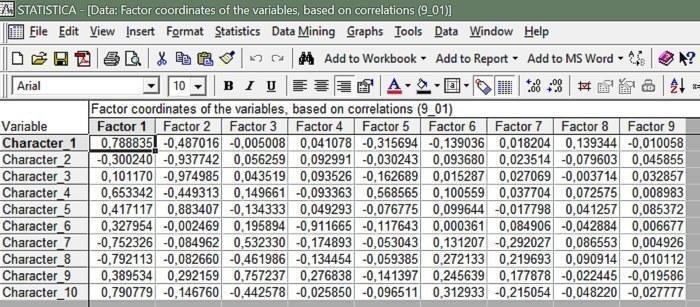
Рис. 9.2.6. Корреляции между исходными признаками и выделенными главными компонентами (Factors)
Кнопка Eigenvalues выводит величины, которые называются собственными значениями главных компонент. В верхней части окна, показанного на рис. 9.2.3, выведены такие значения для нескольких первых компонент; кнопка Scree plot показывает их в удобной для восприятия форме (рис. 9.2.7).
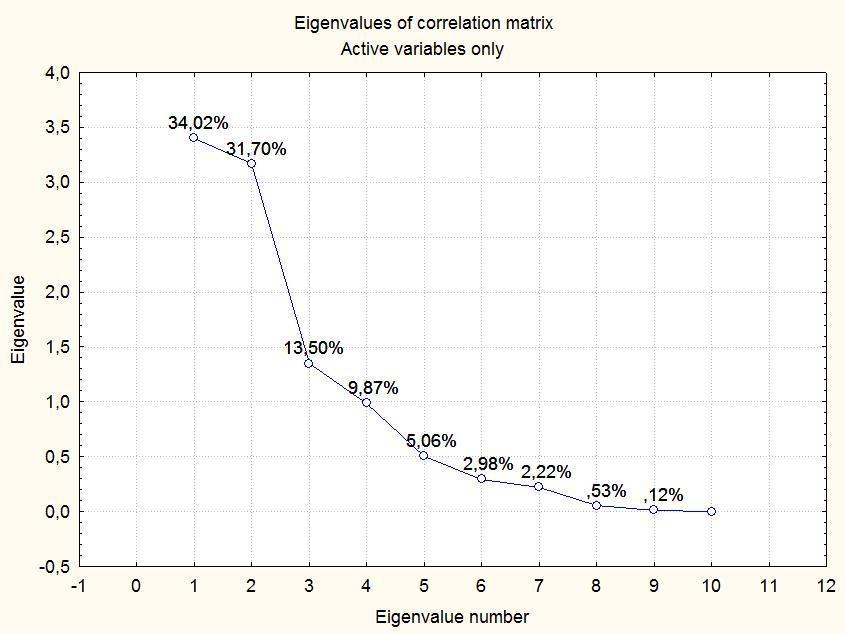
Рис. 9.2.7. Собственные значения выделенных главных компонент и доли отраженной ими общей дисперсии
Для начала надо понять, что именно показывает значение eigenvalue. Это — мера дисперсии, отразившейся на главную компоненту, измеренная в количестве дисперсии, приходившейся на каждый признак в начальных данных. Если eigenvalue первой главной компоненты равен 3,4, это означает, что на нее отражается больше дисперсии, чем на три признака из начального набора. Собственные величины линейно связаны с долей дисперсии, приходящейся на главную компоненту, единое что, сумма собственных значений равна количеству исходных признаков, а сумма долей дисперсии равна 100%.
А что означает, что информацию об изменчивости по 10 признакам удалось отразить в 9 главных компонентах? Что один из начальных признаков был избыточным, не добавлял никакой новой информации. Так и было; на рис. 9.2.8 показано, как был сгенерирован набор точек, отраженный в табл. 9.1.1.
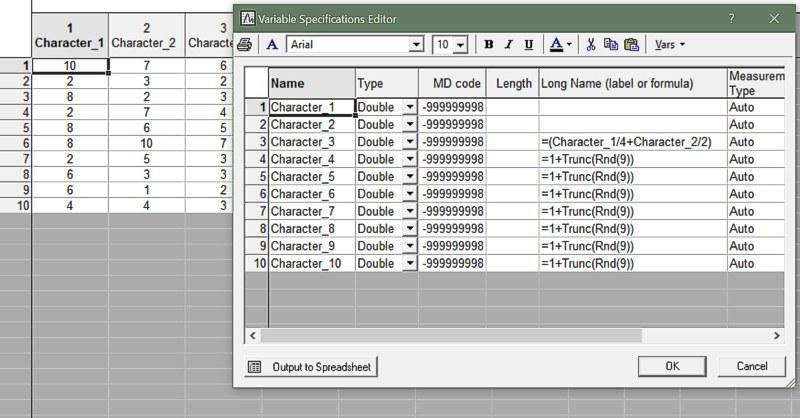
Рис. 9.2.8 Данные в табл. 9.1.1 — искусственные, и здесь видно, как они были сгенерированы