 |
||||
|
← |
Д.А. Шабанов, М.А.Кравченко. Статистический анализ данных в зоологии и экологии |
→ |
||
|
Тема 2. Использование программы Statistica |
Тема 3. Визуализация данных (на примере результатов описания зеленых лягушек) |
|||
|
Биостатистика-01 |
Биостатистика-03 |
|||
Тема 2. Статистические программы и файл-пример для работы с ними
2.1. Разнообразие программ для статистических расчетов
Мы приступили к изучению биологической статистики. Оно может быть организовано двумя разными способами. При первом из них (его можно обозначить "ab ovo") студентам объясняют математические основы изучаемых методов, выводят необходимые формулы и доказывают объясняющие их теоремы. Если студент освоил такой курс, решение конкретных проблем, связанных с тем или иным набором данных в его области исследований оказывается не такой уж сложной задачей. Второй способ ("делай, как я") заключается в том, что студентам показывают, как решать типовые задачи с помощью того или иного инструментария.
Первый способ сложнее. Люди, успешно справившиеся с обучением по первому способу, имеют более высокую подготовку и более универсальны. Однако, в значительной степени, первый способ работает по принципу "все или ничего". Ты или освоил основные подходы и можешь их применять, или не знаешь, что делать и теряешься при необходимости решить простейшие задачи. Второй способ "демократичнее" и позволяет легко решать типичные задачи. Увы, без понимания основ методов люди, которых научили повторять какие-то последовательности действий, но не объяснили их смысл, часто делают ошибки. Еще одним недостатком второго подхода является привыкание к определенным программам (инструментам для решения типовых задач). Естественно, что для разных категорий студентов нужен или первый, или второй способ, или их сочетание. Опыт преподавания биометрии студентам-биологам свидетельствует, что им, преимущественно, нужен подход "делай, как я".
Реализация подхода "делай, как я" требует выбора программ, с помощью которых будет проводиться обучение. Тут приходится выбирать между пятью категориями программ:
— бесплатные любительские и полупрофессиональные программы; их немало, но среди них нет универсальных, и, к тому же, чуть не каждая из них требует своего подхода (хотя некоторые решения следует признать удачными, как, например, этот набор онлайн-калькуляторов);
— вероятно, самая удачная из бесплатных программ, созданная палеонтологами как упрощенный и бесплатный аналог пакета Statistica — программа PAST; скачать последнюю версию самой программы и руководства пользователя к ней можно тут;
— свободное ПО; лидер в этой области — среда R: мощнейший программный пакет (или язык) для статистической обработки (вот его основная страница); в базовом случае требует работы с командной строкой, хотя чаще используется с оболочками наподобие RStudio (скачать его можно тут);
— платное или свободное ПО, не предназначенное для решения статистических задач специально, но представляющее широкие возможности для работы с данными и, в том числе, и их статистической обработки; к этой категории относятся Excell и Access, компоненты Microsoft Office, а также их бесплатные аналоги, как LibreOffice Calc;
«Тут следует отметить ещё одну вещь: ни в коем случае не рекомендуется производить какой-либо статистический анализ в программах электронных таблиц. Не говоря уже о том, что интернет просто забит статьями об ошибках в этих программах и/или в их статистических модулях, это ещё и крайне неверно идеологически. Иначе говоря: Используйте R!». А. Б. Шипунов, Е. М. Балдин “Анализ данных с R”.
— платные профессиональные специальные программы; лидерами рынка в этой области являются программы SPSS и Statistica.
Использование программ пятой категории позволяет в наибольшей степени сосредоточиться на сути решаемых проблем. Увы, оно сопряжено с необходимостью выбора между покупкой дорогой (очень дорогой!) лицензии или использования взломанных, пиратских версий. Тем не менее, по мнению автора, именно такие программы позволяют быстрее всего получить опыт работы с данными, в том числе, и с использованием методов многомерного анализа, требующих сложнейших вычислений.
Один из авторов этого пособия начал работать с программой Statistica фирмы StatSoft (в ее предыдущих реинкарнациях) около 1992 года (тогда она называлась CSS, и она была предназначена для работы в DOS). В то время именно эту программу использовали квалифицированные зоологи Москвы и Киева. Сделанный тогда выбор и предопределил ту программу, на которую ориентировано изложение в этом пособии. Надо признаться, что человеку, который привык работать в программе с оконным интерфейсом, выбирая опции из предложенного списка, чрезвычайно тяжело перейти к работе в режиме командной строки, требующему помнить имена и синтаксис необходимых программ. Впрочем, альтернативы осваивоению среды R для профессионального биолога уже нет.
Авторы планируют расширять данное пособие пояснениями, как реализовать описанные в нем методы в программе PAST и в среде R. До того для знакомства с R можно лишь рекомендовать достаточно многочисленные источники, доступные в Сети, описывающие использование этого пакета. Среди них — посвященные R блоги, в том числе r-analytics и statinr. Очень полезно пройти русскоязычный курс по работе в R.
Есть в Сети и ресурсы, посвященные работе в Statistica; среди них особо можно рекомендовать замечательный портал Статосфера.
2.2. Опис файлу-прикладу Pelophylax_example
Мощными инструментами анализа данных являются средства для построения графиков. Зачастую именно тот или иной способ визуализации собранных данных позволяет понять, какие статистические гипотезы следует проверять в ходе дальнейшего анализа, увидеть интересные или непонятные особенности собранных данных.
В дальнейшем изложении особенности работы программ будут поясняться с испольованием файлов, отражающих результаты настоящих исследований. Одним из таких файлов является таблица данных Pelophylax_example. Для работы с данным конспектом желательно обрабатывать именно этот файл. Его можно получить одним из трех способов. Во-первых, его можно скачать (Pelophylax_example.sta) или получить у автора данного текста. При использовании электронной версии конспекта приведенные ниже данные можно перенести из окна браузера, файла Word или файла .pdf в необходимую программу. Наконец, при использовании печатного конспекта приведенную далее таблицу можно распознать, ввести в необходимые программы и затем использовать ее в дальнейшей работе.
В файле использован фрагмент данных, полученных А.В. Коршуновым при подготовке диссертации на соискание степени кандидата биологических наук (автор искренне благодарен А. В. Коршунову за разрешение использовать результаты его работы). В оригинальном файле содержалось описание нескольких сот лягушек по 16 морфометрическим признакам; в выбранном фрагменте оставлено 57 лягушек и приведены данные об изменчивости у них 7 морфометрических признаков. Структура данных объясняется на примере файла Statistica, потому что именно эта программа позволяет корректнее всего показать текстово-числовые соответствия и спецификации переменных.
Все описанные в файле-примере особи принадлежат к гибридогенному комплексу зеленых лягушек, Pelophylax esculentus complex. Это два родительских вида, прудовая лягушка Pelophylax lessonae (Camerano, 1882) и озерная лягушка, P. ridibundus (Pallas, 1771), а также их диплоидные и триплоидные гибриды, называемые съедобными лягушками, P. esculentus (Linnaeus, 1758). Триплоидные гибриды P. esculentus представлены двумя формами, отличающимися по составу геномов в генотипе. Воспроизводство гибридов связано с феноменом гемиклональной наследственности. Все названные формы лягушек могут образовывать гемиклональные популяционные системы (ГПС), где в ходе совместного размножения передаются как клональные, так и рекомбинантные геномы.
Родительские виды и гибриды обладают определенными внешними особенностями, которые, однако, не позволяют отчетливо отличать их друг от друга. Один из методов доказательной идентификации различных форм зеленых лягушек состоит в использовании проточной ДНК-цитометрии. Взвешенные клетки лягушек с током жидкости проходят через ультрафиолетовый детектор. Они облучаются ультрафиолетовым излучением на длине поглощения ДНК, а затем на той длине, на которой возбужденная ДНК излучает энергию, регистрируется интенсивность флуоресценции (вторичного излучения) клетки. Сравнивая клетки изучаемых особей с реперными клетками (например, трявяной лягушки, Rana temporaria), имеющими точно известную массу ДНК, приходящуюся на клетку, можно определить массу ДНК в изучаемых клетках. Эта масса измеряется в пикограммах, пг. Поскольку известно, что геном P. lessonae имеет массу около 7 пг, а геном P. ridibundus — 8 пг., по массе клеточной ДНК можно определить, какие геномы входят в генотип данной особи.
В файле Pelophylax_example.sta содержатся данные о лягушках с 5 разными генотипами. Обозначая геном P. lessonae как L, а геном P. ridibundus — как R, эти 5 форм можно обозначить как LL, LLR, LR, LRR и RR. Все эти формы встречаются в Харьковской области.
В файле Pelophylax_example.sta строкам (Cases, наблюдениям) соответствуют отдельные особи, а столбцам (Variables, переменным) — их признаки. Характеристика каждой особи включает в себя место сбора, его координаты, а также указание того, относится данная точка к водосборному бассейну Днепра (запад и северо-запад Харьковской области) или Дона (т.е. Северского Донца; большая часть территории области). Кроме того, для каждой лягушки указывается ее пол.
В файле приведены данные о половозрелых лягушках. При возможности выбора, они отбирались так, чтобы для каждой формы лягушек включенные в файл данных особи происходили из разных точек.
Измерение морфометрических признаков проводилось на фиксированных лягушках с помощью штангенциркуля; данные измерялись с точностью до 0,1 мм. Самым существенным из этих признаков является длина тела. Все прочие признаки могут использоваться как в виде абсолютных значений, так и в виде пропорций (отношения данного признака к длине тела). Кроме того, для тех или иных целей могут вычисляться индексы — комплексные признаки, которые вычисляются как некие комбинации исходных морфометрических признаков. Строго говоря, пропорции (отношения промеров к длине тела) тоже являются индексами, но в целях удобства эти понятия проще сузить так, как это предложено в данном абзаце.
Таблица 2.2.1. Данные, включенные в файл Pelophylax_example
Половозрелые зеленые лягушки из Харьковской области (неслучайная выборка)
|
|
Place |
East |
North |
Basin |
Sex |
DNA |
Genotyp |
L |
Ltc |
Fm |
T |
Dp |
Ci |
Cs |
|
1 |
Chernetchina |
35,13 |
50,05 |
Dnieper |
female |
13,95 |
LL |
562 |
187 |
266 |
249 |
62 |
41 |
152 |
|
2 |
Chernetchina |
35,13 |
50,05 |
Dnieper |
female |
13,99 |
LL |
592 |
195 |
281 |
261 |
79 |
37 |
132 |
|
3 |
Chernetchina |
35,13 |
50,05 |
Dnieper |
female |
14,02 |
LL |
603 |
218 |
287 |
281 |
80 |
45 |
158 |
|
4 |
Chernetchina |
35,13 |
50,05 |
Dnieper |
male |
13,95 |
LL |
595 |
199 |
285 |
286 |
75 |
38 |
114 |
|
5 |
Gorodnee |
35,14 |
50,05 |
Dnieper |
male |
16,13 |
RR |
706 |
266 |
326 |
362 |
97 |
37 |
187 |
|
6 |
Krasnocutsk |
35,16 |
50,07 |
Dnieper |
female |
14,03 |
LL |
603 |
194 |
264 |
255 |
76 |
42 |
119 |
|
7 |
Gubarevk |
35,35 |
50,16 |
Dnieper |
male |
16,27 |
RR |
508 |
191 |
259 |
277 |
66 |
27 |
129 |
|
8 |
Sharovka |
35,47 |
50,04 |
Dnieper |
female |
14,91 |
LR |
691 |
227 |
359 |
349 |
98 |
48 |
176 |
|
9 |
Sharovka |
35,47 |
50,04 |
Dnieper |
male |
14,94 |
LR |
659 |
208 |
302 |
300 |
84 |
48 |
166 |
|
10 |
V.Gomols |
36,27 |
49,57 |
Don |
male |
14,80 |
LR |
553 |
210 |
262 |
280 |
85 |
28 |
144 |
|
11 |
Dobr.yar |
36,31 |
49,56 |
Don |
female |
22,60 |
LRR |
715 |
220 |
353 |
344 |
103 |
41 |
155 |
|
12 |
Dobr.yar |
36,31 |
49,56 |
Don |
female |
14,95 |
LR |
707 |
229 |
334 |
332 |
97 |
43 |
150 |
|
13 |
Dobr.yar |
36,31 |
49,56 |
Don |
male |
14,91 |
LR |
714 |
244 |
356 |
341 |
93 |
53 |
181 |
|
14 |
Dobr.yar |
36,31 |
49,56 |
Don |
female |
21,67 |
LLR |
658 |
241 |
306 |
304 |
96 |
34 |
170 |
|
15 |
Dobr.yar |
36,31 |
49,56 |
Don |
male |
21,43 |
LLR |
589 |
216 |
290 |
277 |
77 |
37 |
152 |
|
16 |
Liman |
36,32 |
49,35 |
Don |
male |
16,20 |
RR |
656 |
219 |
352 |
337 |
90 |
36 |
154 |
|
17 |
Gaydary |
36,33 |
49,62 |
Don |
female |
22,79 |
LRR |
742 |
255 |
352 |
356 |
107 |
40 |
174 |
|
18 |
Gaydary |
36,33 |
49,62 |
Don |
female |
22,80 |
LRR |
677 |
294 |
338 |
364 |
108 |
43 |
181 |
|
19 |
Gaydary |
36,33 |
49,62 |
Don |
male |
22,64 |
LRR |
653 |
215 |
315 |
319 |
82 |
38 |
151 |
|
20 |
Gaydary |
36,33 |
49,62 |
Don |
male |
22,81 |
LRR |
691 |
226 |
330 |
334 |
92 |
40 |
167 |
|
21 |
Gaydary |
36,33 |
49,62 |
Don |
male |
22,97 |
LRR |
588 |
206 |
288 |
389 |
91 |
35 |
137 |
|
22 |
Gaydary |
36,33 |
49,62 |
Don |
male |
22,98 |
LRR |
655 |
221 |
328 |
345 |
92 |
45 |
159 |
|
23 |
Gaydary |
36,33 |
49,62 |
Don |
female |
14,88 |
LR |
791 |
299 |
381 |
394 |
116 |
47 |
233 |
|
24 |
S.Gomols |
36,34 |
49,54 |
Don |
female |
15,99 |
RR |
535 |
200 |
265 |
281 |
78 |
32 |
145 |
|
25 |
S.Gomols |
36,34 |
49,54 |
Don |
female |
22,79 |
LRR |
504 |
203 |
231 |
248 |
63 |
31 |
117 |
|
26 |
S.Gomols |
36,34 |
49,54 |
Don |
female |
15,09 |
LR |
877 |
338 |
376 |
423 |
139 |
47 |
227 |
|
27 |
Eschar |
36,35 |
49,47 |
Don |
male |
16,03 |
RR |
686 |
268 |
336 |
361 |
103 |
38 |
197 |
|
28 |
Eschar |
36,35 |
49,47 |
Don |
male |
14,91 |
LR |
561 |
209 |
273 |
285 |
77 |
37 |
161 |
|
29 |
Lipci |
36,38 |
50,21 |
Don |
female |
16,00 |
RR |
701 |
270 |
360 |
376 |
106 |
30 |
178 |
|
30 |
Lipci |
36,38 |
50,21 |
Don |
male |
14,86 |
LR |
668 |
226 |
335 |
328 |
86 |
44 |
175 |
|
31 |
Zhovtneve |
36,46 |
50,08 |
Don |
male |
16,08 |
RR |
930 |
265 |
462 |
461 |
138 |
31 |
202 |
|
32 |
Zhovtneve |
36,46 |
50,08 |
Don |
female |
21,43 |
LLR |
767 |
240 |
349 |
346 |
95 |
44 |
160 |
|
33 |
Zhovtneve |
36,46 |
50,08 |
Don |
female |
21,60 |
LLR |
800 |
262 |
389 |
376 |
116 |
49 |
196 |
|
34 |
Balakleya |
36,48 |
49,27 |
Don |
male |
15,92 |
RR |
792 |
262 |
340 |
357 |
93 |
32 |
172 |
|
35 |
Balakleya |
36,48 |
49,27 |
Don |
male |
22,85 |
LRR |
721 |
278 |
359 |
359 |
104 |
47 |
196 |
|
36 |
Balakleya |
36,48 |
49,27 |
Don |
female |
14,85 |
LR |
641 |
268 |
317 |
323 |
93 |
41 |
173 |
|
37 |
Gatishe |
36,52 |
50,18 |
Don |
female |
14,91 |
LR |
569 |
201 |
260 |
281 |
90 |
36 |
156 |
|
38 |
PechRibhoz |
36,59 |
49,52 |
Don |
male |
14,72 |
LR |
662 |
252 |
321 |
325 |
92 |
43 |
186 |
|
39 |
Izbickoe |
36,73 |
50,20 |
Don |
female |
21,83 |
LLR |
625 |
221 |
303 |
292 |
83 |
37 |
145 |
|
40 |
Kreyd.da |
36,80 |
49,43 |
Don |
male |
22,73 |
LRR |
755 |
268 |
411 |
372 |
106 |
42 |
189 |
|
41 |
Kreyd.da |
36,80 |
49,43 |
Don |
male |
22,74 |
LRR |
564 |
192 |
283 |
293 |
77 |
30 |
139 |
|
42 |
Kreyd.da |
36,80 |
49,43 |
Don |
male |
14,79 |
LR |
650 |
225 |
320 |
319 |
90 |
38 |
164 |
|
43 |
Kreyd.da |
36,80 |
49,43 |
Don |
female |
21,61 |
LLR |
557 |
200 |
251 |
257 |
67 |
33 |
143 |
|
44 |
Kreyd.da |
36,80 |
49,43 |
Don |
male |
21,62 |
LLR |
528 |
196 |
257 |
246 |
66 |
31 |
127 |
|
45 |
Ch.Gusar |
36,86 |
49,41 |
Don |
female |
16,07 |
RR |
542 |
193 |
262 |
282 |
71 |
27 |
129 |
|
46 |
Ch.Gusar |
36,86 |
49,41 |
Don |
male |
16,01 |
RR |
521 |
186 |
243 |
267 |
65 |
28 |
124 |
|
47 |
Verbun.d |
36,89 |
49,42 |
Don |
female |
22,81 |
LRR |
618 |
212 |
288 |
302 |
94 |
32 |
145 |
|
48 |
Verbun.d |
36,89 |
49,42 |
Don |
female |
22,85 |
LRR |
689 |
248 |
316 |
341 |
104 |
37 |
179 |
|
49 |
Verbun.d |
36,89 |
49,42 |
Don |
female |
14,91 |
LR |
543 |
190 |
266 |
273 |
79 |
33 |
127 |
|
50 |
Verbun.d |
36,89 |
49,42 |
Don |
female |
21,50 |
LLR |
616 |
230 |
316 |
298 |
91 |
39 |
155 |
|
51 |
Verbun.d |
36,89 |
49,42 |
Don |
male |
21,61 |
LLR |
528 |
192 |
258 |
262 |
77 |
35 |
128 |
|
52 |
Verbun.d |
36,89 |
49,42 |
Don |
male |
21,64 |
LLR |
574 |
199 |
263 |
267 |
78 |
38 |
146 |
|
53 |
Martova |
36,96 |
49,93 |
Don |
female |
16,18 |
RR |
825 |
315 |
423 |
443 |
124 |
49 |
240 |
|
54 |
Pecheneg |
36,99 |
49,89 |
Don |
female |
16,22 |
RR |
537 |
189 |
259 |
273 |
72 |
28 |
119 |
|
55 |
Ch.Shaht. |
37,03 |
49,18 |
Don |
female |
22,03 |
LLR |
479 |
189 |
238 |
246 |
65 |
27 |
118 |
|
56 |
Petropol |
37,13 |
49,09 |
Don |
female |
16,01 |
RR |
710 |
256 |
339 |
371 |
99 |
34 |
177 |
|
57 |
Veseloe |
37,19 |
49,40 |
Don |
female |
16,11 |
RR |
693 |
247 |
341 |
362 |
104 |
32 |
174 |
Чтобы понять содержащиеся в файле данные, необходимо сопоставить их со спецификациями переменных.
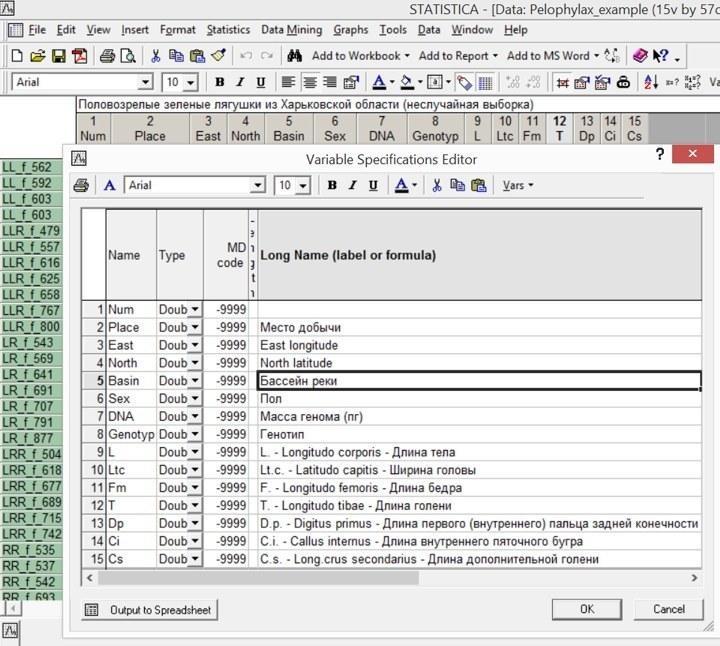
Рис. 2.2.1. Переменные в файле Pelophylax_example.sta
Первый столбец в этом файле содержит обозначение места сбора, второй и третий — географические координаты этой точки, четвертый — обозначение реки, к водосборному бассейну которой относится место сбора. В пятом столбце приведен пол лягушек, в шестом — масса ДНК, приходящейся на каждую клетку (в пг), в седьмом — установленный по массе ДНК генотип. Столбцы с восьмого по четырнадцатый содержат результаты морфометрии (указаны с точностью до 0,1 мм).
Текстово-числовые соответствия с помощью редактора текстовых меток заданы для столбцов 1, 4, 5 и 7. Кодировки для первого столбца (места сбора) для дальнейшей обработки значения не имеют, а для трех других столбцов следует рассмотреть внимательнее.
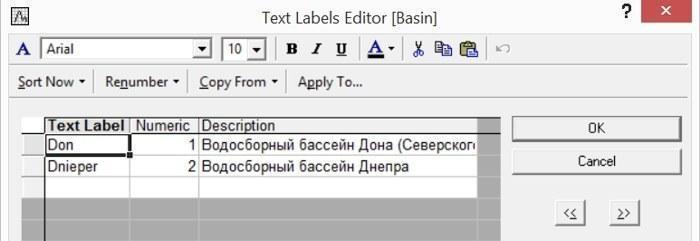
Рис. 2.2.2. Коды переменной Basin в файле Pelophylax_example.sta
Поскольку расселение лягушек происходит в основном по водотокам, граница между бассейнами Днепра и Дона, проходящая по изучаемой территории, весьма существенна с точки зрения распространения различных форм лягушек.
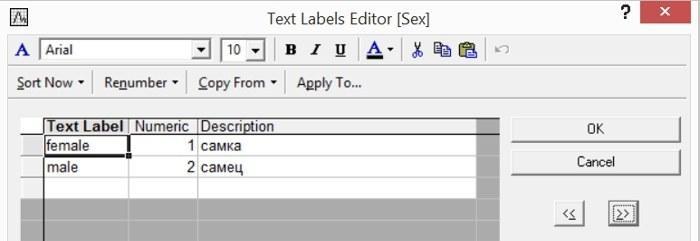
Рис. 2.2.3. Коды переменной Sex в файле Pelophylax_example.sta
Поскольку в данном файле приведены данные исключительно о половозрелых лягушках, для всех их можно определить пол. В некоторых случаях приходится выделять ювенильных особей (молодь, пол которых не может быть определен) и субадультусов (полувзрослых особей).
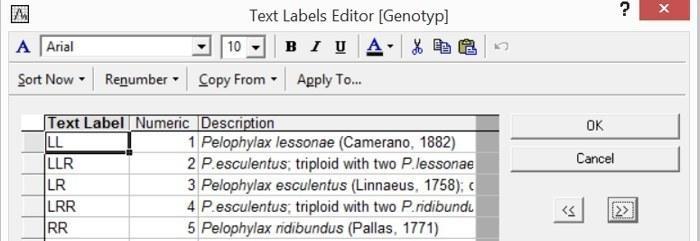
Рис. 2.2.4. Коды переменной Genotip в файле Pelophylax_example.sta
Переменная генотип делит лягушек на 5 изучаемых форм, каждая из которых представлена самками и самцами. Формы LL и RR являются «хорошими» видами, а формы LLR, LR и LRR являются межвидовыми гибридами, которые имеют имя, сравнимое с видовым. Чтобы не вдаваться в сложны терминологические рассуждения о статусе сравниваемых групп лягушек, проще именовать их «формами», трактуя это понятие как обозначение любой группы особей без привязки к их таксономическому статусу.
2.3. Программа Statistica
Итак, программа Statistica, который выпускает фирма StatSoft, предоставляет замечательные возможности для изучения биологической статистики. В настоящее время доступен ряд версий этой программы (на момент написания данного текста последней версией является 13-я). Эта программа распространяется коммерчески и является весьма дорогой; в настоящее время доступны пиратские, «взломанные» версии. Их использование является нарушением буквы закона, и решение об использовании такой версии является делом совести человека, который его принимает. Кроме того, в последнее время появились версии Statictica с лицензиями на использование в учебных целях. Их существование оправдывает подробное описание использование программы Statictica, содержащееся в данном пособии. Важно напомнить, что в данном пособии речь идет об обучении использованию программы Statistica, т.е. это пособие можно рассматривать как рекламу данной программы.
В настоящее время широко распространены как оригинальные, англоязычные версии программы Statistica, так и ее различные локализации (переводы на русский язык). Следует заверить, что непрофессионально переведенным русскоязычными вариантами программы пользоваться сложнее, чем оригинальным, даже для человека, который не знает английского языка. В настоящее время существует 10-я версия программы Statistica, переведенная на русский язык российским представительством производителя, фирмы StatSoft.
Комментарии по инсталляции (установке) программы здесь приводиться не будут: любой установочный пакет программы содержит указания о том, как это следует делать. Следует обратить внимание на важное обстоятельство, касающееся удобства использования установленной программой. Statistica может использоваться не только для исследования, но и в решении серьезных производственных задач (например, для формализованной обработки данных о клиентах в банках). Для таких задач полезной может быть способность программы собрать в единый комплекс результаты разных способов обработки какого-то объекта. Поэтому Statistica способна формировать «рабочие тетради», Workbooks, собирающие в единое целое все результаты действий пользователя.
При исследовании биологического материала часто генерируются графики и таблицы, которые не сохранять не нужно, ведь работа биолога часто носит поисковый характер. В такой ситуации проще выводить результаты работы в виде отдельных окон.
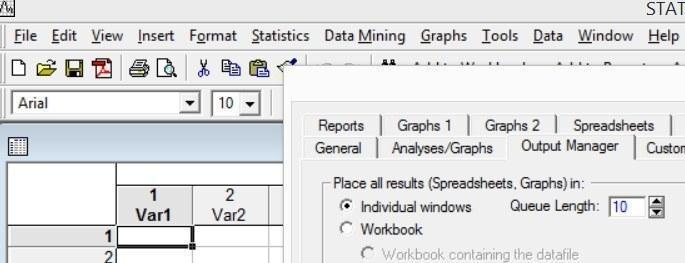
Рис. 2.3.1. Чтобы переключить программу Statistica на режим вывода в отдельных окнах, следует пройти по пути Tools / Options / Output Manager (Сервис / Параметры / Диспетчер вывода) и отметить соответствующий вариант вывода
Сразу после инсталляции программа предложит работать с инструментом для поиска данных (DataMiner) или настроить режим запуска. Самое простое — закрыть стартовое окно и окно DataMiner и перейти к работе с таблицами данных.
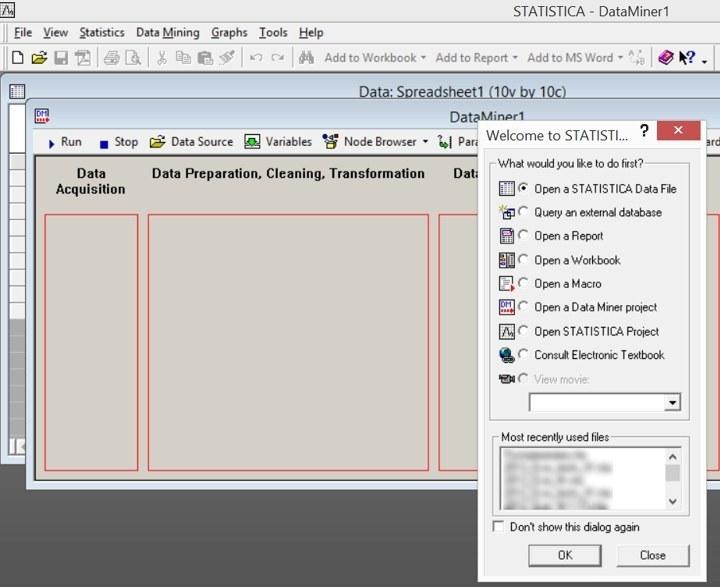
Рис. 2.3.2. Начало работы с программой Statistica. Для нашей работы нужно окно с таблицей данных, другие окна можно закрыть
2.4. Структура таблицы данных Statistica
Таблица данных в программе Statistica организованна весьма жестким образом: она состоит из строк, которым присвоено название наблюдения (Cases) и столбцам, которые названы переменными (Variables). Строки и столбцы можно добавлять (Add...), перемещать (Move...), копировать (Copy...) и удалять (Delete...).
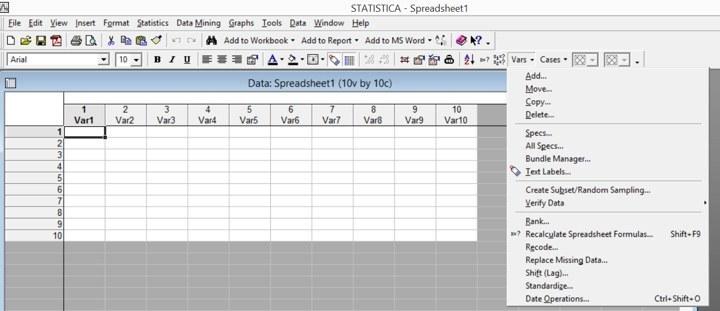
Рис. 2.4.1. Для работы с переменными и наблюдениями служат соответствующие пункты меню (в данном случае выделено меню для управления наборами переменных Variables, "Vars").
При редактировании данных они вводятся в ячейки таблицы. Однократный щелчок мышью на ячейке выделит ее, двойной (или нажатие клавиши F2 при выделенной ячейке) переведет в режим ее редактирования. Рамочка вокруг выделенной ячейки станет тоньше, и внутри нее появится курсор. Теперь в ячейку можно вводить данные.
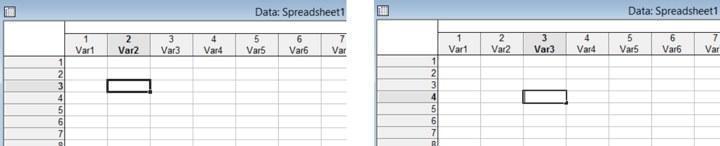
Рис. 2.4.2. Ячейка на рисунке слева выделена (выделить можно одну или большее количество ячеек). Ячейка справа находится в режиме редактирования, можно изменить ее содержание (например, добавить в нее данные)
Нажав на левую клавишу мыши и проведя курсором над таблицей данных можно выделить блок — прямоугольную область из ячеек.
Над заголовками столбцов находится поле, в которое можно записать название таблицы — заголовок таблицы.
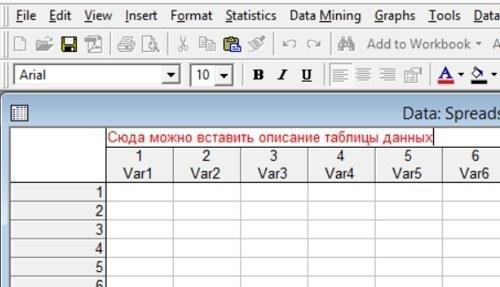
Рис. 2.4.3. Вставить в заголовок таблицы какие-то пояснения того, что она из себя представляет, бывает довольно полезно
Самый первый столбец таблицы содержит имена наблюдений. Двойной щелчок по имени включает режим его редактирования. Не менее важный способ управления именами состоит в использовании диспетчера имен наблюдений.
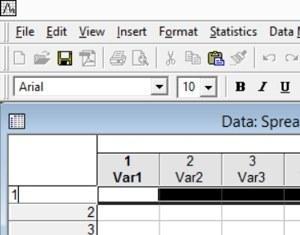
Рис. 2.4.4. Редактирование имен наблюдений
Забегая вперед, можно сказать, что в графических результатах многих статистических анализов целесообразно подписывать имена наблюдений, соответствующих отдельным объектам. Поэтому надо постараться сделать так, чтобы эти имена были достаточно короткими и достаточно выразительными.
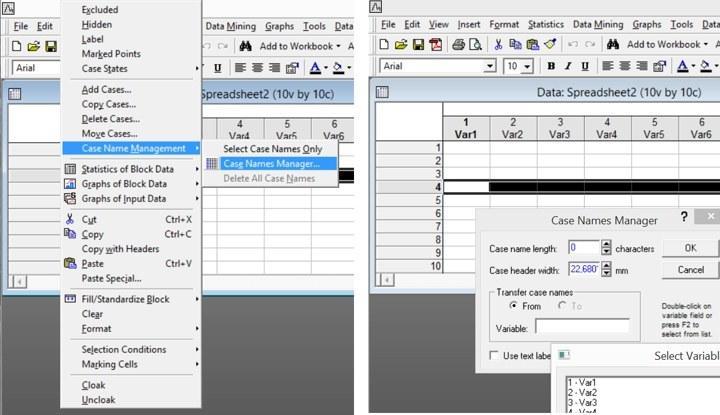
Рис. 2.4.5. Чтобы вызвать диспетчер имен наблюдений, необходимо щелкнуть правой кнопкой мыши на каком-то имени наблюдения и пройти по пути Case Name Management / Case Names Manager. С помощью этого диспетчера можно переместить в имена содержимое какой-то переменной, или наоборот, создать переменную, которая будет содержать имена наблюдений. Для того, чтобы вызвать список переменных, нужно дважды щелкнуть мышью в окошке Variable
Кроме прочего, с помощью диспетчера имен наблюдений можно менять ширину окна, в котором размещаются заголовки.
Для удобства работы с таблицей данных желательно настроить ширину столбцов так, чтобы в них полностью помещались заголовки столбцов и введенные в ячейки значения, но при этом они не были слишком широкими. Это можно сделать вручную, перемещая границы между столбцами (между их заголовками), а можно и выполнить автоматически.

Рис. 2.4.6. Двойной щелчок мышью на границе между заголовками столбцов приводит к автоматической настройке их ширины. В первом случае измениться ширина только одного столбца (по правому краю которого производится щелчок), а во втором – всех выделенных столбцов, то есть всей таблицы
В ряде случаев бывает необходимо перестроить таблицу данных, сделав ее строки столбцами, а столбцы — строками (эта операция называется транспонированием). Это делается при помощи команды Data / Transpose (Данные / Транспонировать). У этой команды есть два варианта — транспонировать выделенный блок (он обязательно должен иметь одинаковое количество строк и столбцов) и транспонировать весь файл (количество столбцов и строк в нем может отличаться).
2.5. Действия с выделенными ячейками в Statictica
Данные в выделенных ячейках можно перемещать, а заданные в соседних ячейках арифметические прогрессии — продлевать.
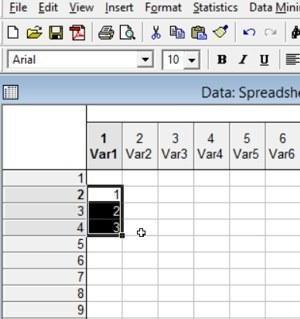
Рис. 2.5.1. Группа ячеек выделена; курсор находится на других ячейках и имеет вид «пустотелого» плюса
При выполнении этих операций следует обращать внимание на изменение формы курсора.
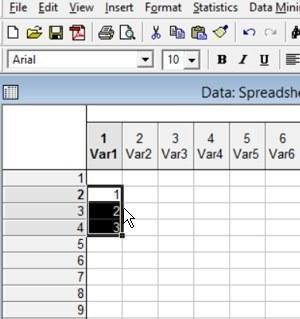
Рис. 2.5.2. Курсор находится на краю выделенного блока; выполнив в этом положении двойной щелчок и «потянув» мышью, блок данных можно переместить на требуемое место
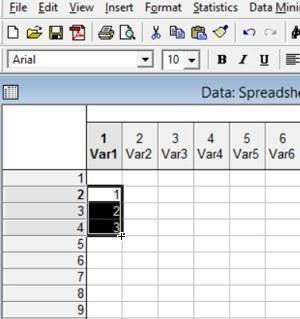
Рис. 2.5.3. Курсор находится в правом нижнем углу выделенного блока; выполнив в этом положении двойной щелчок и «потянув» мышью, можно продолжить арифметическую прогрессию, заданную в блоке, на соседние ячейки
Если при «растягивании» арифметической прогрессии область, которая должна быть заполнена создаваемым рядом, выйдет за пределы таблицы, программа спросит, расширить таблицу до требуемого объема или ограничить прогрессию имеющимися ячейками.
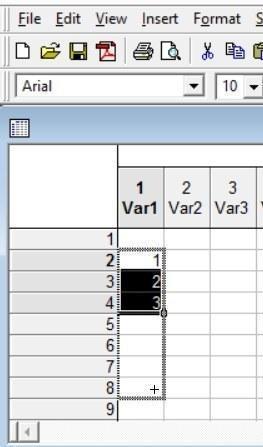
Рис. 2.5.4. «Растягивание» арифметической прогрессии на несколько ячеек
Наконец, следует отметить, что при нажатой клавише Ctrl можно выделить несколько групп ячеек, не обязательно формирующих прямоугольный блок.
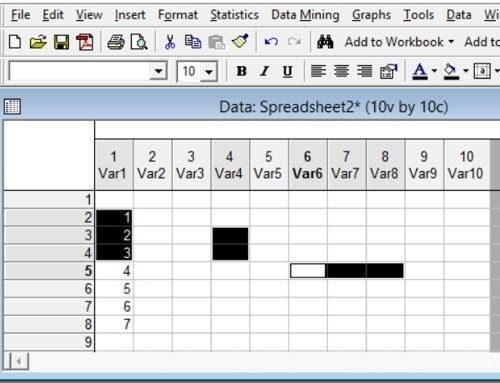
Рис. 2.5.5. Чтобы выделить ячейки таким образом, необходимо удерживать нажатой клавишу Ctrl
С выделенным блоком можно производить разнообразные действия, в частности, удалять содержимое ячеек или производить в них контекстную замену.
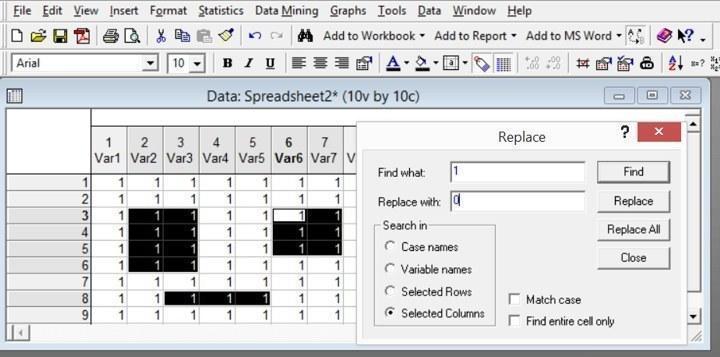
Рис. 2.5.6. Чтобы осуществить контекстную замену, необходимо пройти по пути Edit / Replace (Правка / Замена), нажать Ctrl+H или нажать на соответствующую кнопку на «приборной панели» (на рисунке эта кнопка "нажата", она расположена недалеко от правого верхнего угла рисунка)
Контекстная замена является эффективным методом для работы с большими файлами данных, позволяя избежать многократного повторения рутинных действий.
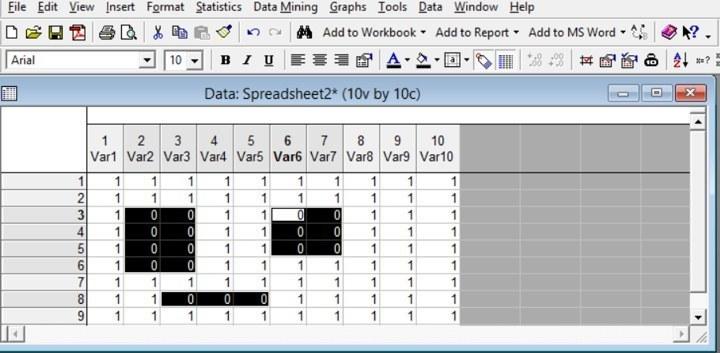
Рис. 2.5.7. Результат контекстной замены, показанной на предыдущем рисунке
2.6. Работа со строками и столбцами в Statictica
Основные инструменты для работы со строками и столбцами таблицы данных находятся в пунктах меню, предусмотренных по умолчанию, «Переменные» и «Наблюдения». Те же функции, которые находятся в этих меню, доступны через опцию «Данные» в основном меню программы.
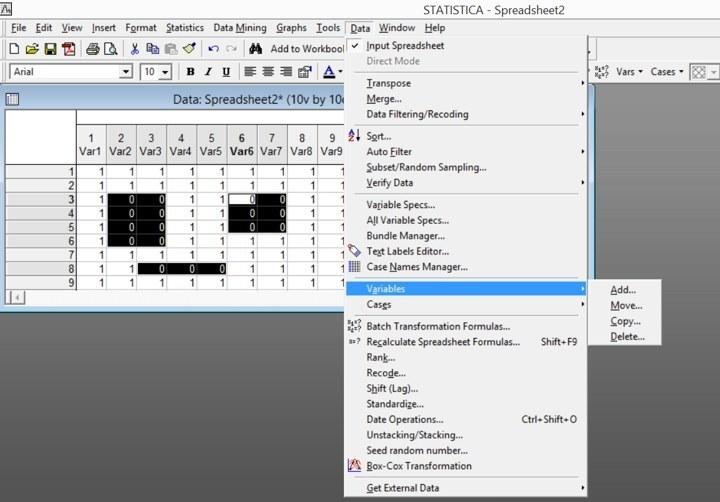
Рис. 2.6.1. Управление столбцами и строками доступно через меню Data (Данные) или через специальные меню Vars (Переменные) и Cases (Наблюдения)
По мере заполнения таблицы в программе Statistica данными часто возникает необходимость в добавлении столбцов и строк.
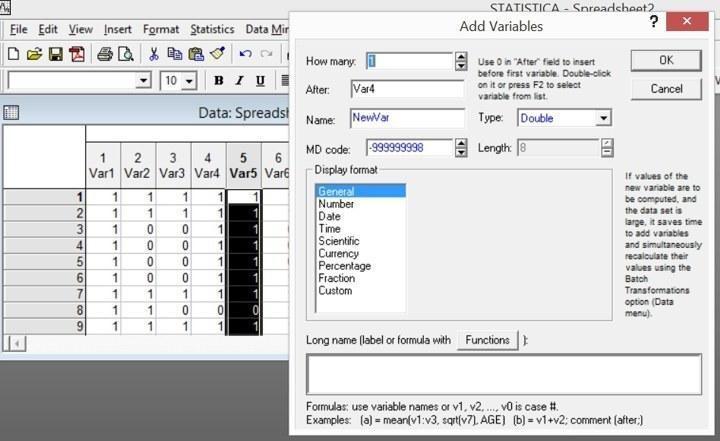
Рис. 2.6.2. При добавлении переменных программа Statistica по умолчанию предлагает вставить их перед тем столбцом, в котором находится выделенная ячейка
При добавлении столбцов можно указать их количество, место (после какого столбца они добавляются, шаблон названия (по умолчанию — NewVar) и некоторые другие параметры, подробнее рассмотренные позже. При перемещении столбцов также можно указать с какого столбца начинается перемещаемая группа, каким заканчивается и в какое место эта группа столбцов должна быть перемещена.
Аналогично происходит добавление строк (наблюдений).
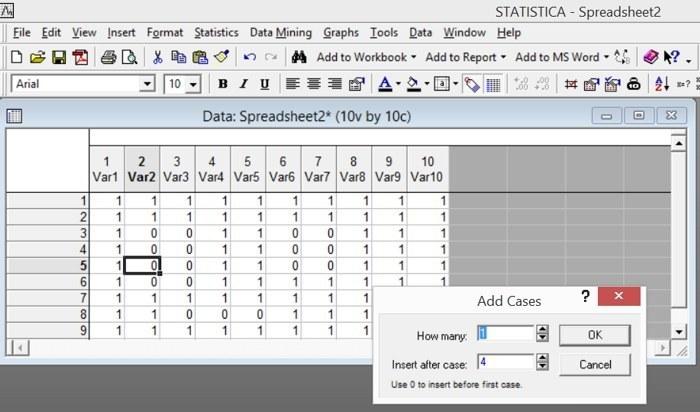
Рис. 2.6.3. При добавлении строк их также по умолчанию предлагается вставлять перед той строкой, в которой находится выделенная ячейка
2.7. Спецификации переменных в Statictica
В таблице данных программы Statistica над каждым столбцом находится его заготовок. Заголовки пронумерованы порядковыми номерами и по умолчанию называются Var 1, Var 2 и т.д. Чтобы изменить свойства столбца, нужно дважды щелкнуть на его заголовке.
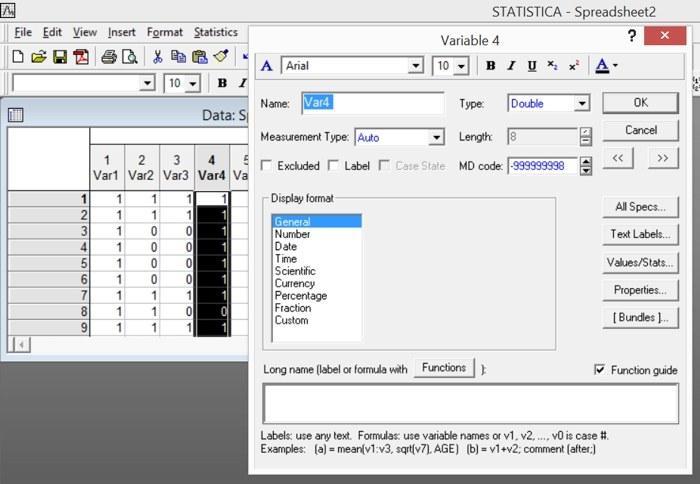
Рис. 2.7.1. Дважды щелкнув на заголовке столбца можно перейти в режим спецификации — редактирования свойств переменной. Здесь можно задать ее название, тип данных, шрифт, количество отображаемых десятичных знаков (для числового режима), формулу для ее пересчета а также некоторые другие свойства
От одной спецификации легко переходить к соседним, используя кнопки со стрелками, расположенные в верхней правой части диалогового окна (под кнопкой «Отмена»). Чтобы увидеть весь список переменных и редактировать любую из них, следует выбрать режим Vars / All Specs... (Переменные / Все спецификации...). Из окна спецификаций одной переменной к редактору можно перейти с помощью кнопки All Specs... (Все спецификации…).
В данном пособии мы не будем подробно рассматривать типы переменных, допустимые в программе Statistica. По умолчанию используется двойной тип переменных, позволяющий записывать в них как текстовые, так и числовые данные (об этом будет подробнее рассказано позже). Кроме того, программа предоставляет возможность для выбора формата данных. При указании числового формата становится активным окно, в котором можно указать, до какого количества десятичных данных следует округлять данные, показываемые на экране. Не нужно бояться округлять данные: программа Statistica все равно хранит и использует в вычислениях их в их полном объеме, с высокой точностью, но для зрительного восприятия данных проще предоставлять их в округленном виде.
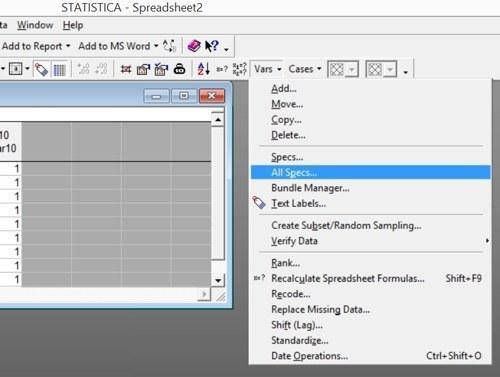
Рис. 2.7.2. Открывание редактора спецификаций переменных
В первую очередь студентам следует освоить работу с названиями переменных и формулами для их вычисления.
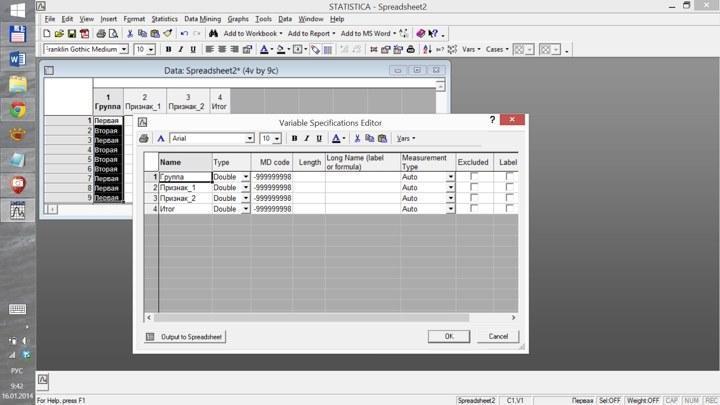
Рис. 2.7.3. Редактор спецификаций переменных
2.8. Числовая и текстовая формы данных в Statictica
Данные, введенные в ячейки таблицы данных, могут иметь как числовой, так и текстовый вид. В режиме, при котором десятичным разделителем является запятая, выражение «1,1» будет интерпретировано как число (одна целая и одна десятая), а «1.1» — как текст.
Данные в программе Statistica могут иметь разный тип. В том, который данные имеют по умолчанию, двойном типе данных, всем текстовым значениям, введенным в данный столбец, придается в соответствие определенное число. Перейти из режима отображения текстовых данных в режим отображения числовых можно, поставив или сняв галочку напротив пункта Display Text Lables (Показать текстовые метки) в меню View (Вид).
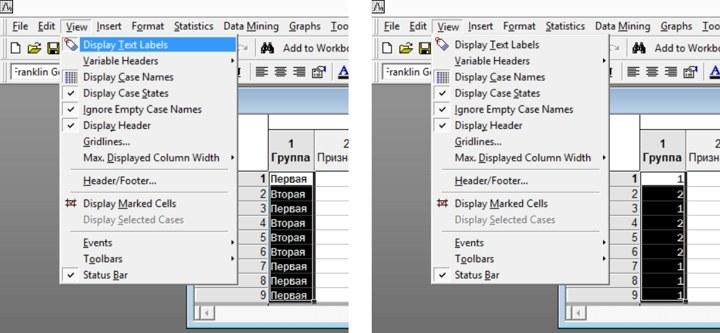
Рис. 2.8.1. В статистике можно переходить от текстового отображения данных к числовому и обратно: View / Display Text Lables (Вид / Показать текстовые метки). На этих рисунках разница в отображении видна для переменной «Группа»
Соответствие между текстовыми и числовыми значениями задается в редакторе текстовых меток (Text Lables...), который для каждого конкретного столбца можно вызвать, пройдя по пути Vars / Text Lables... (Переменные / Текстовые метки) или вызвать из окна спецификаций переменной, как это показано на рисунке.
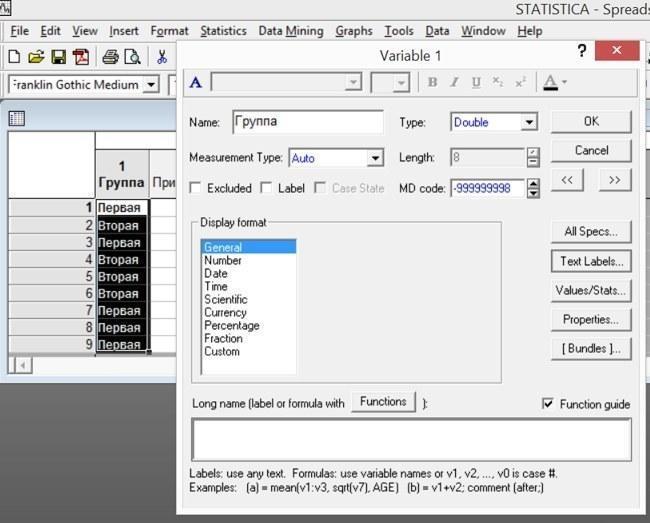
Рис. 2.8.2. Двойной щелчок на заголовке первой переменной (т.е. на надписи "1 Группа") вызвал окно спецификаций переменной. В этом окне есть кнопка для входа в редактор текстовых меток для этой переменной – Text Lables...
По умолчанию новое значение, введенное в определенный столбец, получает числовое значение 101, следующее — 102 и так далее. Эти соответствия могут быть изменены; при этом Statistica «переспросит», следует ли перекодировать имеющиеся данные в новые кодировки. Так, в показанном на рисунке примере текстово-численные соответствия установлены для переменной «Группа». Такие соответствия облегчают набор данных: в соответствующей ячейке не нужно словами писать «первая», и достаточно просто поставить единичку.
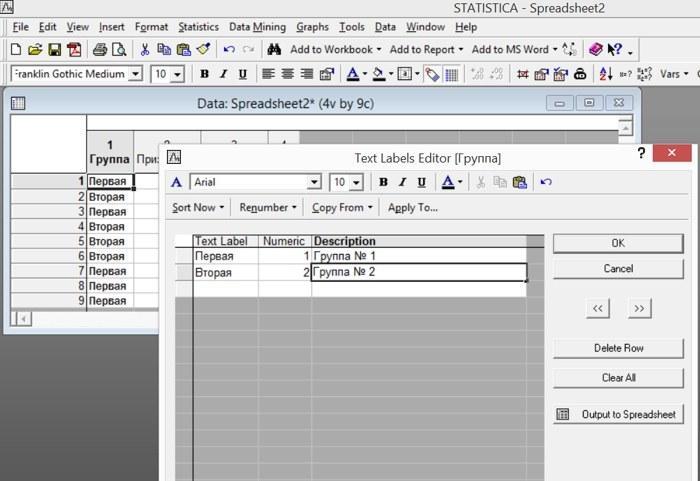
Рис. 2.8.3. Редактор текстовых меток позволяет задать соответствия между текстовыми и числовыми данными. Обратите внимание на кнопки со стрелочками: с их помощью можно переходить в режим редактирования текстовых меток соседних переменных
Иногда в процессе набора данных в ячейки попадают какие-то неверные текстовые фрагменты. Даже если они оказываются удалены из файла данных, они вместе со своими численными соответствиями остаются в редакторе текстовых меток, накапливаясь там как нежелательный «мусор». Такие неиспользуемые данные следует удалять (выделить и нажать кнопку «Delete Row»).
В процессе использования программы можно столкнуться с проблемами неадекватного отображения кириллических шрифтов. Одним из универсальных советов является рекомендация использовать латиницу (например, все названия и обозначения писать на английском языке). Если все-таки использовать русский язык, могут возникать проблемы с его отображением.
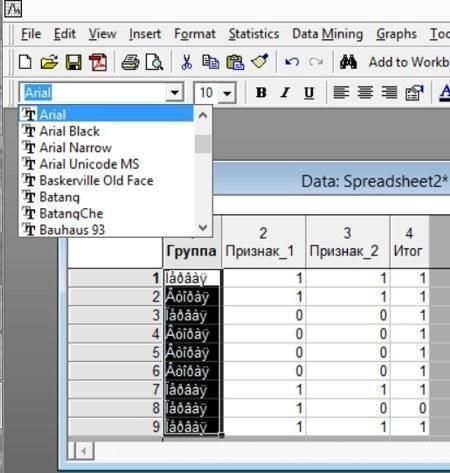
Рис. 2.8.4. Пример неправильного отображения кириллических символов (т.н. "козявушки")
Такие проблемы можно исправить, подобрав правильно отображающийся шрифт.
2.9. Формулы для пересчета данных в Statictica
В нижней части окна спецификаций переменной (или в правой части редактора спецификаций переменных) можно задать формулы, по которым происходит пересчет данных. Формула начинается со знака «=», который показывает, что данную переменную необходимо пересчитать. В формула используются арифметические знаки (+, -, *, /), знак возведения в степень (** или ^), скобки, а также сокращенные обозначения различных функций. Подсказки по синтаксису этих обозначений появляются во всплывающих окнах (хинтах).
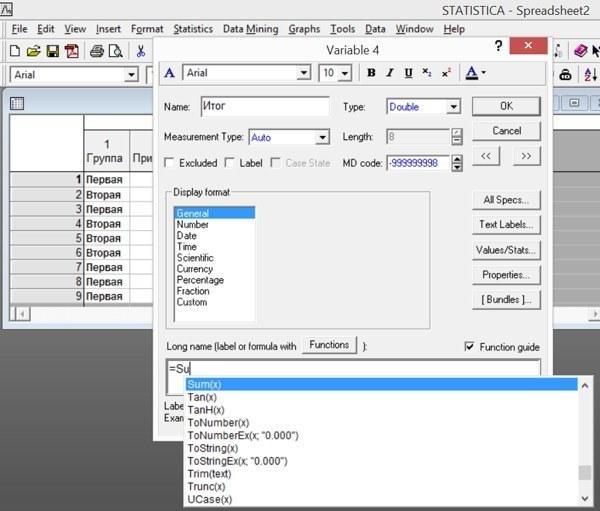
Рис. 2.9.1. Если в окошке Function guide (Просмотр функций) стоит галочка, программа Statistica будет предлагать подсказки по мере набора формул в окне спецификаций переменной
В формулах можно использовать обозначения других переменных. Их можно обозначать или указывая их имена, или обозначая их по номерам после буквы «v» (сокращения от «variable»), например, v1 или v 15.
В формулах можно приводить логические условия. Это выражения, которые заключаются в скобки и содержат внутри символ «=» или знаки «>» больше, «<» меньше, «>=» больше или равно, «<=» меньше или равно. Например, переменная, в окне для формул которой введено =( v1=10) примет значение 1, если переменная 1 равна 10 (верное логическое условие считается равным единице) или 0, если переменная 1 не равна 10 (неверное логическое условие считается равным нолю).
Выражение, которое придаст переменной значение 1 в том случае, если переменная Number меньше 10 и 2, если переменная Number больше или равна 10, может выглядеть так: =(Number<10)+(Number>=10)*2. Как можно убедиться, эта формула содержит два логических условия. Если переменная Number меньше 10, первое слагаемое равно 1, а второе равно 0; если соответствующая переменная больше или равна 10, первое слагаемое равно 0, а второе равно 2.
При указании формул для переменных полезно сопровождать их комментариями, которые облегчат понимание того, для чего эти формулы нужны.
В том случае, если формула написана в соответствии с правилами и ссылается на переменные, которые имеются в файле, при закрытии окна спецификации переменных Statistica предложит пересчитать переменную. Подсчет будет произведен только для тех строк, в которых используемые формулой ячейки содержат какие-то данные.
Пересчитать переменные в любой необходимый момент можно при помощи команды Vars / Recalculate Spreadsheet Formulas... (Переменные / Пересчитать), клавиатурного сочетания Shift+F9 или при нажатии на соответствующую кнопку.
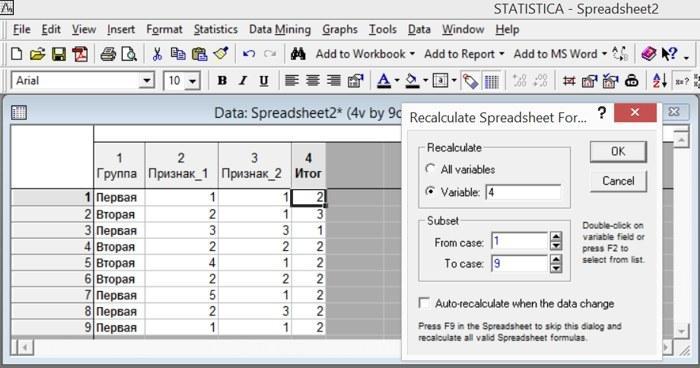
Рис. 2.9.2. Окно пересчета данных. Курсор показывает на кнопку, которая его вызывает (слева вверху, «нажата»). Обратите внимание на опцию Auto-recalculate when the data change (Автопересчет при изменении данных)
В некоторых случаях бывает удобно включить режим автопересчета при изменении данных. В этом случае, стоит лишь изменить какое-то содержимое одной из ячеек, все остальные значения, использующие то, которое было изменено, будут автоматически пересчитаны. Впрочем, этот режим удобен не всегда. Например, при его использовании режим «отката» (возврата последнего изменения), который вызывается командами Edit / Undo... (Правка / Отменить), Ctrl+Z или нажатием на соответствующую кнопку, отменяет не те изменения, которые были сделаны пользователем, а результаты пересчета.
При работе с формулами следует учитывать, что ячейки, которые не содержат никаких данных, на самом деле содержат определенное число – код пропущенных данных. По умолчанию это число равно -9999, но его можно изменить в окне спецификаций переменной или редакторе спецификаций переменных. Большинство используемых в формулах функций «работают» только с ячейками, куда введены какие-то иные данные, чем код пропущенных данных. В те ячейки, содержимое которых пересчитывается по формулам, ссылающимся на пропущенные данные, тоже вставляется код пропущенных данных. Для формул, работающих со столбцами, где есть пропущенные данные, может быть полезно использовать логические условия наподобие IsMD(v1), которое принимает значение 1 если в данной строке соответствующей переменной нет данных (точнее, находится код пропущенных данных), и значение 0 — когда данные в соответствующей ячейке есть.
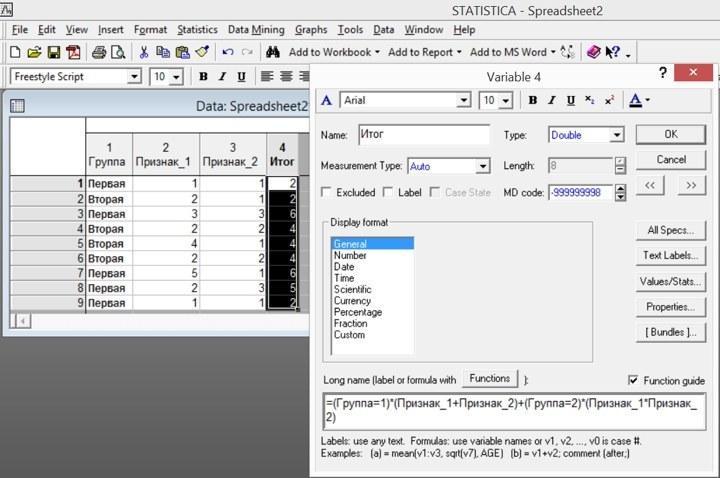
Рис. 2.9.3. Для переменной «Итог» введена формула, вычисляющая сумму переменных «Признак_1» и «Признак_2» для объектов (строк) из первой группы и произведение этих признаков для объектов из второй группы. Чтобы формула работала, необходимо, чтобы первой группе в редакторе текстовых меток соответствовал код 1, а второй – 2. Приведенный пример не очень удачен, так как в нем используются русские имена для переменных
В том случае, если с файлом проводится достаточно длительная работа, обозначать переменные по их номерам (к примеру, как v 15) нецелесообразно. Добавление, удаление или перемещение переменных (напомним, что их общий список доступен из меню All Specs) приведет к изменению их нумерации и собьет работу использующих их формул. В формулах лучше указывать имена переменных. Из этого следуют пожелания по тому, как следует называть переменные. В их названиях нежелательны пробелы и арифметические знаки. Если в имени переменной очень хочется использовать пробел, его лучше заменить нижним подчеркиванием (_). Если все-таки эти правила нарушаются, имя переменной в формуле можно взять в одинарные кавычки, но это является дополнительным усложнением формулы, повышающим шансы запутаться при ее написании, а особенно — при поиске ошибок в формуле, которая работает не так, как хочется.