Ложь, наглая ложь и…
…статистика. На сегодня ее использование — почти обязательное условие выполнения научной работы во многих отраслях, в том числе и в зоологии1. Не будет большой новостью, если я скажу, что статистику чаще используют неверно, чем верно. Причины этого различны, и мы постараемся обсудить некоторые из них.
Еще одно вводное замечание. Ошибки в применении статистики делают самые разные специалисты, в том числе и титулованные и — по настоящему! — квалифицированные. Я буду приводить примеры из конкретных работ своих коллег. Эти люди — не хуже прочих, и причина, по которой я цитирую именно их, — знакомство с ними или интерес к их работам. Я не хочу нарушать их инкогнито. Более того, я даже не могу назвать объект их работы. В зоологии есть замечательное свойство, отраженное Борисом Заходером в сказке «Кит и кот». Там, когда происходит неожиданная коллизия (кит и кот поменялись местами), вертолет доставляет на палубу китобойного судна группу ответственных лиц, в составе которой «академик по китам, академик по котам».
И в ответ на китобазу
Вертолет садится сразу.
В нем ответственные лица
Прилетели из столицы:
Доктора, профессора,
Медицинская сестра,
Академик по китам,
Академик по котам,
С ними семьдесят студентов,
Тридцать пять корреспондентов,
Два редактора с корректором,
Кинохроника с прожектором,
Юные натуралисты
И другие специалисты.
Мест в академии всем не хватит, но люди «в теме» понимают, что по китам - это N., а по котам - это или L., или M. Обсуждая конкретные истории, я буду называть определенные объекты. Так вот — это не те объекты. Будем считать, что любое сходство описанных обстоятельств с реальными работами - случайность.
Итак, приступим к рассмотрению коллекции затруднений, которые возникают при использовании статистики в зоологии.
Ошибки плюс вера в «объективность»
Начну с простого случая. Мой коллега — полевик, который лучше управляется с ружьем, чем с компьютером. Он настрелял немерено… ну, допустим, «зайцев» и попросил меня помочь про этих зайцев что-то посчитать. К какой программе обращается в такой ситуации украинский или российский зоолог? Нередко к пакету Statistica от компании StatSoft. Это — серьезный и дорогой продукт. Он так дорог, что без обсуждения специфики отечественных научных и образовательных учреждений вообще непонятно, как он мог получить столь широкое распространение2. Одна из причин его популярности — разнообразие предлагаемых функций и высокое качество, но определенную роль играет и консерватизм пользователей. Лет пятнадцать назад московские и киевские зоологи передавали друг другу дискеты с инсталлятором статистического пакета CSS — предыдущей инкарнации Statistica. Так или иначе, этот пакет уже стал как минимум полустандартом.
Так вот, я уточнил, что хочет мой коллега-"зайцевед», и сделал ему файл. Тот посадил за компьютер студента, который забил в этот файл результаты измерений. Дальше вышло вот что. Я спешу на встречу, а мой коллега ловит меня в коридоре и тащит к компьютеру: «покажи, как считать эту… корреляцию». Я показываю: надо вызвать такое-то окошко, здесь выбрать те признаки, связь между которыми надо рассмотреть, и вот тут выскочит результат. Сказав это, я убегаю.
Через неделю меня ловит другой мой коллега, спец в английском языке. Исследователь «зайцев» попросил его перевести тезисы, предназначенные для отправки на Всемирный териологический3 конгресс. Переводчик удивлен: «Ты действительно насчитал ему достоверную отрицательную корреляцию между длиной тела и весом?"
Встречаю коллегу-«зайцеведа» и спрашиваю: «Вы ведь сами их стреляли? Могли ли вы не обратить внимание на то, что чем добыча крупнее, тем она легче?» «Ты знаешь, я, в общем, и сам удивился, чего ж я это не заметил. Но это же мои субъективные впечатления, а тут машина со всей присущей ей объективностью…"
Пересчитываю его результаты, смотрю корреляцию. Она, ясное дело, положительна. Как там получилась отрицательная — теперь не установить. Хорошо хоть тезисы на конгресс не успели уйти - было б там веселье.
Наивность моего коллеги обнажила общую беду — мы доверяем результатам вычислений больше, чем себе самим. Ошибки делают все, но разумные люди так организуют процесс работы, чтобы ошибки «всплывали» и благодаря этому могли быть исправлены. Здесь нелишне вспомнить один простой рецепт.
С помощью статистики мы ищем те или иные тенденции, отраженные в разнообразии изучаемого материала. Но и тот механизм, которым мы наделены от природы (глаза и мозг), позволяет неплохо вычленять тенденции, скрытые в разнообразии материала. Надо просто «скормить» им информацию в удобоваримом виде. Один из хороших способов не запутаться в критериях — строить графики. Когда вы видите, как располагаются точки, можно перепроверить любой свой вывод. Если какая-то точка «вылетает» (располагается в стороне от основной совокупности), вы можете определить, с каким случаем она связана. Иногда для этого удобно отсортировать строки в окне с данными по возрастанию интересующего вас признака. А для того, чтобы потом можно было вернуться к исходному порядку, удобно сделать столбец с «правильными» номерами строк, сортировка по которому вернет таблицу в исходное состояние.
И никогда не нужно забывать, что «машина» знает только то, что мы ей смогли сообщить. А избыточное доверие к результатам вычислений… Приведу следующий пример.
Установки программы «по умолчанию»
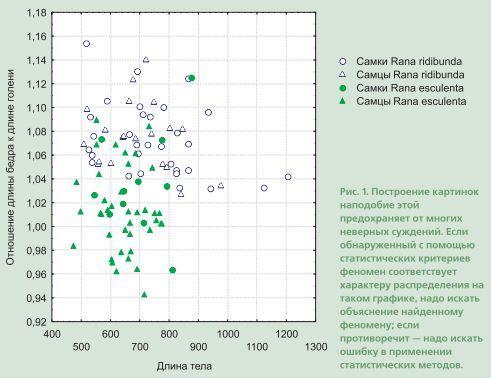
Идет защита докторской диссертации крупного специалиста по… ну, скажем, «мышам». Автор представляет материал со всей Евразии — десятки видов, десятки признаков. Для определения сходства и различия между видами используется кластерный анализ. Для самок и самцов строятся независимые кладограммы (древовидные графы, отражающие уровень сходства внутри иерархически соподчиненных групп). Кладограмма самцов имеет достаточно обычный вид, а вот самок выглядит странно (рис. 2). Эти кладограммы вставлены в разосланный по городам и весям автореферат докторской и демонстрируются на защите.
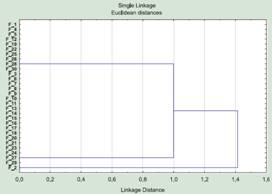
Рис. 2. Результаты кластеризации самок 30 видов «мышей» по 50 признакам (данные условны).
Диссертант говорит, что изменчивость самок и самцов подчиняется разным закономерностям, и обращает внимание на то, что самки формируют две группы, внутри которых они не отличаются друг от друга. На основании этого ему удается сделать некоторые выводы и предположения. Ни один из специалистов, присутствующих на защите или приславших отзывы на автореферат, не задает элементарный вопрос: почему же тогда их относят к разным видам и даже разным группам видов, раз по всем изученным признакам они идентичны?
Ларчик открывается просто. Дело в том, что при проведении кластерного анализа в программе Statistica необходимо решить, что же делать с пустыми ячейками в таблице объекты/признаки. По умолчанию в соответствующем модуле (рис. 3) стоит опция «Casewise», означающая, что признак, по которому не определен хотя бы один из объектов, вообще выбрасывается из рассмотрения. В нашем примере это означает, что особи классифицировались лишь по двум признакам4, каждый из которых может принимать всего два значения (например, есть кисточки на ушах или нет).
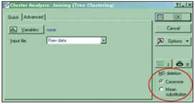
Рис. 3. Злополучное окошко в диалоге, относящемся к кластерному анализу
Чтобы компенсировать «дыры» в данных, необходимо выбрать опцию «Mean substitution». При таком выборе отсутствующее значение заменится средним для всей совокупности объектов и окажет наименьшее влияние на конечный результат (разумеется, еще лучшее решение — определить все признаки для всех объектов). Выбрав замену средним значением, мы можем получить дерево, напоминающее приведенное для самцов (рис. 4).
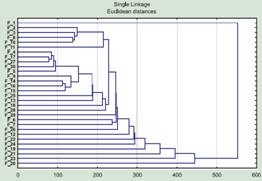
Рис. 4. Опять кластеризация самок, по тем же данным, что на рис 2, только для признаков с отсутствующими данными включена замена средним значением, а не исключение признака из анализа.
Непонимание сути метода
На престижном научном форуме была представлена работа, касающаяся выделения морфотипов (групп организмов, объединенных сходством) в популяциях животных, которые мы назовем «воронами». На протяжении многих лет я интересуюсь гипотетической возможностью корректно описать популяционное разнообразие посредством выделения нескольких морфотипов особей, чтобы потом сравнивать популяции по частотам этих типов. И вот я вижу работу, в которой это удалось сделать…
Наличие нескольких типов в популяции «ворон» иллюстрируется картиной, которая аналогична показанной на рис. 5. Здесь использовано объединение в кластеры по методу Уорда (Ward’s method). Этот метод строит кластеры (группы) так, чтобы получающаяся внутри групповая дисперсия была минимальна. К сожалению, кластеры, которые выделялись при исследованиях одной выборки, не соответствовали кластерам, которые удавалось увидеть аналогичными методами в другой.
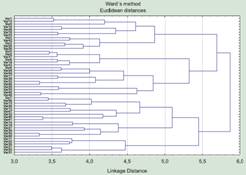
Рис. 5. Результаты кластеризации 100 объектов, охарактеризованных по 100 случайным признакам, с использованием метода Уорда. Видно образование ряда групп с уровнем сходства около 4 единиц
Вернувшись в гостиницу, я построил таблицу, заполненную шумом (так, формула «=Rnd(1)» в заголовке столбца приводит к его заполнению псевдослучайными числами от 0 до 1). Кластеризовав эти случайные объекты с использованием тех же методов, я получил «морфотипы», объединенные примерно на том же уровне сходства, что и в работе про «ворон» (рис. 5). Что характерно, на ее автора это не произвело никакого впечатления: «Ну и что, что и в случайном материале выделяются группы? У меня же материал не случайный!"
Выделение типов имеет смысл только в том случае, если они отделены друг от друга определенным разрывом. Если мы анализируем с помощью методов кластерного анализа совокупность объектов, относящихся к отграниченным друг от друга типам, построенные в ходе анализа кластеры будут соответствовать этим типам. Если же типов в структуре самого материала нет, анализ все равно построит кластеры: ничем другим работа его алгоритмов закончиться не может.
Магия «достоверности»
Описанные выше ошибки в использовании статистики были яркими, но достаточно редкими. Теперь я с содроганием от собственной наглости5 должен приступить к обсуждению ошибки, которая является нормой для множества работ, как в моей узкой специальности, так и в изучении смежных групп.
Как систематик описывает разнообразие организмов? Упрощая, можно сказать, что он собирает в разных регионах серии подобных животных, сравнивает их друг с другом и решает, относятся ли они к одной форме, к разным подвидам или к разным видам. Новые подвиды и виды описывают, указывая их отличия от старых, ранее известных. В старые времена это сравнение проводилось в основном на основании интуиции систематика: его профессиональный взгляд мог (или не мог) выделить признаки, на основании которых принималось то или иное решение. Сейчас свое решение принято подтверждать статистическими методами. Как это делают чаще всего?
Собирают две серии объектов (например, уклеек из бассейна реки А и из бассейна реки Б), описывают их по максимальному количеству признаков, допускающих их представление в виде чисел, а потом сравнивают по всем этим признакам по критериям Стьюдента и Фишера (см. врезку). Послушная Statisticа подсветит красным те признаки, по которым найдутся достоверные отличия. Дальше смотрим, сколько таких признаков найдется и на какой статус отличий они потянут. Например, в авторитетнейшем для моей отрасли науки отечественном методическом сборнике один из классиков указывал, что два достоверных отличия — мало для описания подвида, а вот три — в самый раз.
Врезка
Выражение «выборки сравнили по Стьюденту-Фишеру» несет в себе определенную некорректность. Еще чаще встречается некорректное употребление этих методов.
Критерий Стьюдента (t-критерий) представляет собой разницу средних двух выборок, отнесенную к стандартной ошибке разности выборочных средних (которая, в свою очередь, зависит от уровня изменчивости обеих выборок). Для каждого числа степеней свободы (зависящего от численности выборок) вычислено, с какой вероятностью случайность формирования выборок может привести к тому или иному значению t-критерия. Если t-критерий для определенного числа степеней свободы превосходит пороговое значение (например, возникающее в силу случайности с вероятностью 0,05), разницу выборок можно считать достоверной.
Автором этого самого популярного (к сожалению, не благодаря его достоинствам, а в силу его простоты) статистического метода является английский химик Уильям Госсет, работавший на пивоваренную компанию Guinness. По уставу фирмы, ее сотрудники не имели права публиковать результаты исследований, выполненных в рамках служебной деятельности. Поэтому результаты своей работы Госсет опубликовал в 1908 году под псевдонимом Student.
Принципиально важно, что t-критерий определен только для случая, когда сравниваются две выборки с одинаковыми дисперсиями и нормальными распределениями. Если дисперсии в выборках отличаются, этот факт можно показать с помощью F-критерия (требование нормальности распределения остается при этом в силе). F-критерий предложен американским статистиком Джорджем Снедекором и назван им в честь сэра Рональда Фишера, английского генетика, создателя дисперсионного анализа. Этот критерий представляет собой отношение двух дисперсий. Как и для t-критерия, для него известно распределение вероятности случайных отклонений для разных степеней свободы.
Итак, t-критерий позволяет оценить, какова вероятность того, что отличия средних двух выборок отражают лишь случайные процессы при их формировании, а F-критерий позволяет сделать то же самое в отношении меры их изменчивости. Увы, нормальность распределения - важнейшее ограничение применимости этих критериев.
Вопреки господствующему мнению, нормальные распределения — редкость в биологии. Одним из классических примеров «нормального» распределения является распределение людей по их росту. Но взгляните на фотографию: распределения мужчин и женщин по росту разные. На фотографии только здоровые люди, и нет больных с нарушениями гормонального баланса. А подумайте, что будет, если к этому распределению добавить стариков и детей!

Нормальность распределения возникает тогда, когда на величину действует много несвязанных слабых факторов. На биологическое разнообразие обычно влияет целый букет «сильных» факторов, связанных друг с другом букетом же корреляций. Эти факторы — пол, возраст, место в иерархической структуре популяции и многое другое. Увы, со «Стьюдентом-Фишером» в большинстве случаев лучше попрощаться.
Для описания новых видов, к счастью, требуют что-то сверх отличий по метрическим признакам (хотя якобы совсем недавно кому-то удалось описать массу новых видов моллюсков почти исключительно на основании достоверных отличий формы раковины). А для обоснования существования подвидов указанные рассуждения используются вовсю.
Корректны ли они? Конечно, нет. И дело не только в том, что t- и F-критерий применимы только для данных с нормальным распределением. Дело в другом. «Стьюдент-Фишер» дает ответ на вопрос, какова вероятность того, что два сравниваемых распределения одного и того же признака взяты из одной генеральной совокупности, и различия между ними — результат случайности при составлении выборки. Если эта вероятность (p) ниже какого-то уровня (например, 0,05), мы можем рискнуть и принять гипотезу, что выборки взяты из разных совокупностей. Это и называется достоверностью различий. И все. Отсюда есть два следствия.
Первое. Когда мы сравниваем уклеек из двух разных рек, мы и так с самого начала знаем, что это выборки из разных совокупностей. Второе. При уровне значимости 0,05 достоверное отличие — это такое отличие, которое возникает не чаще, чем в одном случае из двадцати. А если мы будем сравнивать выборки по ста признакам (или сто пар выборок по одному признаку), математическое ожидание «достоверных» отличий составит целых пять штук!
Беру две группы по пятьдесят объектов, характеризую их по ста признакам, заполняя столбцы шумом. Сравниваю по «Стьюденту-Фишеру». Получаю шесть «достоверных» отличий, из которых три штуки влезают в первый же скрин (рис. 6). Ну что, теперь можно анализировать, какие именно признаки оказались достоверно отличающимися, и делать на основании этого глубокомысленные выводы о специфике эволюции уклеек в бассейнах двух рек…
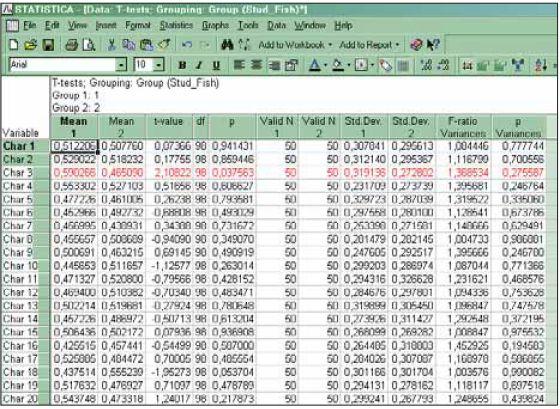
Рис. 6. Сравнение двух групп объектов по совокупности случайных признаков позволяет найти определенное
количество «достоверных» отличий.
Мои рассуждения кажутся вам примитивными? Возьмите любой сборник или журнал с подобными по методологии работами и вы сами сможете найти примеры такого употребления статистических методов.
Что же делать? Для сравнения выборок по признакам, которые не подчиняются нормальному распределению, использовать непараметрические методы. Для сравнения нескольких объектов одновременно использовать дисперсионный анализ. Для сравнения одновременно по нескольким признакам использовать многомерные критерии. Для оценки уровня отличий между разными совокупностями вычислять фенетические дистанции (численные меры того, насколько отличаются друг от друга две выборки). И аккуратнее использовать статистические методы.
Самообман
Мы начали статью с особенностей работы в программе Statistica. Однако ясно, что сама по себе проблема использования численных методов в биологии шире этой программы. В следующем примере речь идет о математическом моделировании эволюции, однако и эту работу можно рассматривать как связанную с биометрией и статистикой. В отличие от предыдущих, этот пример невозможно сделать анонимным — уж слишком широкую огласку он получил. Описывая его, я сошлюсь на «Происхождение видов» Дарвина. Чтобы объяснить, при чем тут Дарвин, нужно немного уйти в сторону.
Должен признаться, что серьезно «подсев» на классическую музыку, категорически не приемлю сборников наподобие «The best of Bach». Авторы таких подборок берут на себя труд подправлять классиков. Великие композиторы иногда могли сочинить что-либо стоящее, но, вероятно, по причине недостатка вкуса, вставляли хитовые мелодии в занудные симфонии. Впрочем, если из устаревшего произведения выкинуть все ненужное, оно может сойти и для современного, придирчивого слушателя. Еще одна примета времени — переложения устаревшей музыки на новый лад. Я своими ушами слышал сетования, что у Баха не было в распоряжении электрогитары — какую хорошую музыку он мог бы написать6!
В издании классиков науки тоже существует подобная тенденция. Аналогией Баха, из которого выброшено все ненужное, а остаток переложен на электрогитару, может быть «Происхождение видов» Дарвина под редакцией А. В. Яблокова и Б. М. Медникова7. Те места, где Дарвин сомневался или осторожно нащупывал мысль, выкинуты бестрепетной рукой. Оставленный дарвиновский текст изрядно улучшен редакторскими комментариями и вставками. Поскольку Дарвин не был знаком с «Аксиомами биологии» Медникова8, пришлось ему кое-что разъяснить. Кроме многого другого, в «Происхождение видов» добавлено описание машинного эксперимента, выполненного В. В. Меншуткиным совместно с самим Медниковым, — тут инкогнито авторов никак не сохранишь… Хотя речь идет о довольно старом результате, он часто цитируется до сих пор, так что его анализ по-прежнему остается актуальным.
Моделировалась эволюция позвоночных. Была описана «биосфера», в которой могло существовать определенное количество организмов. Было задано описание позвоночного, в котором перечислено определенное количество качеств (наличия/отсутствия тех или иных органов и свойств). В начале в модельную биосферу поместили существо типа ланцетника — примитивный вариант, в котором приспособления позвоночных находятся лишь в потенции. «Размножение» осуществлялось путем копирования имеющихся в биосфере организмов. В ходе копирования были возможны ошибки — «мутации». После каждого цикла размножения возникал избыток организмов, и программа удаляла описания менее приспособленных организмов, а «генотипы» более приспособленных отсылала на следующее копирование.
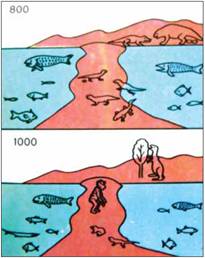
Рис. 7. Описания двух из этапов машинной эволюции, «переведенные» на язык изображений (Дарвин (!), цит. соч., с. 342)
В результате этого эксперимента удалось доказать, что ход эволюции предопределен и неизбежно ведет к появлению разума. В эксперименте Меншуткина-Медникова «ланцетники» дали разнообразных «рыб», имевших три пары парных плавников, а затем вышли на сушу в виде шестиногих существ. В результате эволюции наземной жизни возникли существа типа кентавров - перемещавшиеся на четырех ногах организмы со свободными для труда передними конечностями. У них был крупный мозг и способствующая развитию разума социальная жизнь.
Достигнув этого этапа, экспериментаторы «отмотали» машинное время назад и населили сушу четвероногими существами. О чудо! Теперь возникший в ходе эволюции разум оказался двуног. Итак, удалось доказать, что в эволюции есть определенная свобода, но в целом ее ход предрешен.
Я считаю, что эволюция направлена, но убежден в этом не благодаря эксперименту Медникова-Меншуткина, а вопреки ему. И дело не в том, что позвоночные не могли быть шестиногими (см. врезку). Дело в том, как в данном эксперименте оценивалась приспособленность «организмов».
Врезка
Наземные позвоночные — потомки рыб. Конечности возникли из парных плавников рыб. Освоение суши четвероногими позвоночными — следствие того, что рыбы имеют две пары парных плавников: грудные (передние) и брюшные (задние). У предков рыб раньше возникли непарные плавники, как движитель, обеспечивавший прямолинейное плавание при извиваниях тела. Эволюционное становление рыб было связано с приспособлением к хищному питанию и сопровождалось приобретением челюстей (для схватывания добычи) и парных плавников (рулей, обеспечивавших повороты). Парные плавники формировались из тянущейся вдоль тела боковой складки. Как видно по реконструкции одной из самых древних рыб, когда-то парных плавников было больше. У показанной на рисунке рыбы промежуточные плавники превращены в шипы. А как рули эффективнее всего работали передний и задний участки когда-то единой плавниковой складки. Вспомните, как проще развернуть лодку — сделать боковое движение веслом у носа или у кормы, но не в середине корпуса.
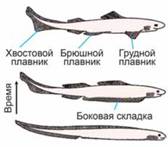
Можно ли учесть такие взаимосвязи в модели? В сложной можно. Но если эти взаимосвязи поняты, задача уже практически решена. А надеяться, что «машина» сама «догадается» о подобных взаимосвязях, - непростительная наивность.
Посвященная попыткам управлять экономикой из одного центра книга нобелевского лауреата Фридриха фон Хайека называется «Пагубная самонадеянность». Никакой план не может предусмотреть то, что определяется множеством людей в их конкретных рыночных взаимодействиях. Еще пагубнее самонадеянная вера, что можно заранее знать, что выберет, а что отбракует естественный отбор. Модельная биосфера, которая сможет это предсказать, должна быть столь же сложна, как и настоящая. А в модели Меншуткина-Медникова был лишь один способ отделять удачи от неудач - ввести априорную оценку, в которой приспособленным считалось то, что восторжествовало в ходе действительной земной эволюции. Программе задали, что самое приспособленное существо - это разумное существо. Для разума нужны свободные конечности, большой мозг и социальная жизнь. Иными словами, модели задали конечное состояние и способ его достижения (с преодолением случайных ошибок). Кого-то удивляет, что модель пришла туда, куда ее направили с самого начала?
Интересно, что экспериментаторы «выключали» эволюцию, когда у них возникало разумное существо. Они понимали, что дальнейшее развитие модели будет топтанием на месте? По крайней мере, они могли обосновать такое решение тем, что после появления разума биологическую эволюцию вытесняет социальная. Так или иначе, экспериментаторы убедили в предопределенности эволюции не только многочисленных читателей, но и себя самих. Дарвинизм обвиняют в логическом круге: приспособленность объясняют как способность выживать, а выживание считают следствием приспособленности. Все же думаю, что склонный к осторожным и всесторонним размышлениям Дарвин не попался бы в ту ловушку, куда заманили самих себя Меншуткин и Медников. Впрочем, это не помешало их эксперименту попасть в издание одной из самых главных книг в истории биологии ("ЭВМ подтвердила Дарвина").
Что в сухом остатке? Пример самообмана. Увы, к той же категории можно отнести и другие примеры, рассмотренные в этой статье. Как ни парадоксально, статистика - широко распространенный способ для обмана не только других, но и себя самого.
Не осмеял ли я в этой статье сверх меры собственную отрасль науки? Если и осмеял, надеюсь, что не скомпрометировал. К счастью, если речь идет о квалифицированных специалистах, их способность к целостному восприятию материала позволяет преодолевать неблагоприятные последствия неверного употребления статистики. На самом деле, многие из статистических методов предназначены для того, чтобы в хаосе случайных отклонений вычленить проступающие сквозь помехи глубинные причины наблюдаемой изменчивости. Это высокое предназначение статистики заставляет относиться к ней уважительно, и оно же подталкивает нас к некритичной вере в результаты «объективных» доказательств.
Возвращаясь к заглавию статьи, зададимся вопросом: что же лучше - наглая ложь или самообман? Не знаю. Но без всякой связи со статистикой (и призыва обманывать других, а не себя самого) процитирую принцип, который кажется мне весьма глубоким.
Одной из сложностей становления раннего христианства было определение его отношения с иудаизмом — традиционной религией евреев. В конечном счете христианство дистанцировалось от иудаизма, что способствовало его превращению в мировую религию. Это изменение коснулось даже трактовок многих евангельских событий. В каноническом тексте Евангелия от Луки Иисус по поводу сбора колосьев в субботу (то есть нарушения ветхозаветных правил) говорит: «Сын человеческий есть господин и субботы». Известен и апокрифический вариант этого Евангелия, где содержится иной, по всей вероятности, более древний (и возможно, близкий действительному Иисусу) вариант9. Видя человека, работающего в субботу, Иисус говорит: «Человек, если ты знаешь, что делаешь, будь благословен, но если ты не знаешь, ты проклят, как преступающий закон».
1Статья нашего постоянного автора, харьковского зоолога Дмитрия Шабанова посвящена весьма острой проблеме в современной науке (далеко не только биологии!), все больше полагающейся на машинную мудрость. Прогресс аналитических методов позволяет даже в относительно скромных по масштабу работах (например, студенческих проектах) накапливать немыслимые прежде информационные массивы. Естественно, без помощи компьютерной обработки результатов проследить закономерности в получающихся гигантских простынях таблиц очень трудно. Здесь-то исследователя и подстерегают всяческие неприятности, чаще всего связанные с бездумным обращением с данными. Владислав Бирюков
2Когда-то автор попытался легально учить студентов программе Statistica и ради этого пробовал «достучаться» до российского представительства фирмы-изготовителя. Безуспешно
3Териология - наука о млекопитающих
4Последние версии Statistica отказываются работать по одному признаку, а предыдущие соглашались даже на это. В цитируемой диссертации был использован всего один признак, но, создавая аналогичную картинку, я вынужден был добавить еще один, чтобы ублажить более привередливую версию программы
5И выражением благодарности замечательному специалисту в области биометрии С. Н. Шамраю, который помог мне разобраться в этом вопросе, но не несет никакой моральной ответственности за мои возможные ошибки
6Не верю, что за всю историю человечества удалось создать инструмент, более богатый значимыми для человеческой природы интонациями, чем рояль, и более подходящий для выражения эмоций, чем скрипка, альт или виолончель
7Дарвин Ч. Происхождение видов путем естественного отбора: Кн. для учителя / Коммент. А. В. Яблокова, Б. М. Медникова. - М.: Просвещение, 1986 - 383 с
8Довольно известная и, по моему мнению, бессмысленная в силу самой постановки задачи попытка догматизировать биологию
9Свенцицкая И.С. Раннее христианство: страницы истории. - М.: Политиздат, 1987. - С. 217
Д. Шабанов. Ложь, наглая ложь и… // Компьютерра, М., 2006. – № 25–26 (645–646)
Коментарі
статья вызвала восторг.
статья вызвала восторг.
во-первых, редко где можно встретить такие конкретные указания на ошибки, а не абстрактные советы.
во-вторых, мне чисто интуитивно всегда казалось, что при всём уважении к математическому аппарату, его использование не должно быть основным критерием "научности" работы. т.к. при такой постановке вопроса часто статистика в работах "рисуется" только для того, чтоб показать графики со звёздочками, свидетельствующие о серьёзности исследования.
на одной из аспирантских конференций довелось увидеть "палочки" доверительных интервалов так и оставленные, видимо, в экселе стандартного размера для всех столбиков диаграммы. на вопрос: а вас ничего не смущает? была обида и уверенное настаивание на том, что это мол программа сама так сделала, ей виднее...
и много подобного, к сожалению, встречается. а всё из-за того, что некоторые считают, что работы без статистической обработки показывать людям нельзя. мне же кажется, что иногда лучше грамотно представить феноменологию без псевдодостоверностей, чем откровенно бессмысленную статистику.
ещё раз спасибо за статью.
http://probioukr.blogspot.com/
Вы привели как раз ключевую фразу:
"программа сама так сделала" - выражение отношения к компьютеру не как к инструменту, а его примитивно-магического восприятия. "Он так захотел - что же мне делать...?"