|
|
||||
|
БІОСИСТЕМИ. БІОСФЕРА
ЕКОСИСТЕМИ. ПОПУЛЯЦІЇ
ОРГАНІЗМИ У ДОВКІЛЛІ
ЛЮДСТВО ТА ЙОГО ДОЛЯ
|
||||
|
Додаток VI. Oгляд команд R |
|
|||

Додаток VI. Огляд команд R
Матеріал цього додатку засновано на «шпаргалці», яка розташована на офіціальній сторінці проєкту R, а також на її версії.
Допомога
help(topic), ?topic — довідка щодо topic
help.search("pattern"), ??pattern — глобальний пошук pattern
help(package = ) — довідка щодо вказаного пакету
help.start() — запустити допомогу в браузері
apropos(what) — імена об'єктів, що відповідають what
args(name) — аргументи команди name
example(topic) — приклади використання topic
Оточення
ls() — список усіх об'єктів
rm(x) — видалити об'єкт
dir() — показати усі файли в поточній директорії
getwd() — вказати поточну директорію
setwd(dir) — змінити поточну директорію на dir
Огляд об'єктів
str(object) — внутрішня структура об'єкта object
summary(object) — загальна інформація щодо об'єкта object
dput(x) — отримати представлення об'єкту в R-синтаксисе
head(x) — подивитися початкові рядки об'єкта
tail(x) — подивитися останні рядки об'єкта
Ввід та вивід
library(package) — підключити пакет package
save(file, ...) — зберігає вказані об'єкти у двойковому XDR-форматі, що не залежить від платформи
load() — завантажує дані, що були збережені раніше командою save()
read.table — зчитує таблицю даних і створює по ним data.frame
write.table — виводить на друк об'єкт, конвертуючи його в data.frame
read.csv — зчитує csv-файл
re1ad.delim — зчитування даних, що розділені знаками табуляції
save.image — зберігає усі об'єкты у файл
cat(..., file= , sep= ) — зберігає аргументи, конкатенуючи їх через sep
sink(file) — виводить результати виконання інших команд в файл у режимі реального часу до моменту виклику цієї ж команди без аргументів
Створення об'єктів
from:to — генерує послідовність чисел від from до to з кроком 1, наприклад 1:3
с(...) — поєднує аргументи у вектор, наприклад c(1, 2, 3)
seq(from, to, by = ) — генерує послідовність чисел від from до to з кроком by
seq(from, to, len = ) — генерує послідовність числел від from до to довжини len
rep(x, times) — повторює x times разів
list(...) — створює перелік об'єктів
data.frame(...) — створює фрейм даних
array(data, dims) — створює з data багатовимірний масив з розмірністю dim
matrix(data, nrow = , ncol = , byrow = ) — створює з data матрицю nrow на ncol, порядок заповнення визначає byrow
factor(x, levels = ) — створює з x фактор з рівнями levels
gl(n, k, length = n*k, labels = 1:n) — створює фактор из n рівнів, кожен з яких повторюється k раз довжини length з іменами labels
rbind(...) — поєднує аргументи по рядках
cbind(...) — поєднує аргументи по стовпцях
Індексування
Вектори
x[n] — n-тий елемент
x[-n] — усі елементи, крім n-того
x[1:n] — перші n елементів
x[-(1:n)] — усі елементи, крім перших n
x[c(1,4,2)] — елементи з індексами, що перелічені
x["name"] — елемент з ім'ям, яке вказано
x[x > 3] — усі елементи, більші за 3
x[x > 3 & x < 5] — усі елементи між 3 и 5
x[x %in% c("a","and","the")] — усі елементи з множини, яка задана
Переліки
x[n] — перелік, що складається з елемента n
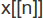 — n-тий елемент переліку
— n-тий елемент переліку
 — елемент переліку з ім'ям name
— елемент переліку з ім'ям name
x$name — елемент переліку з ім'ям name
Матриці
x[i, j] — елемент на перехрещенні i-ого рядка та j-ого стовпця
x[i,] — i-ий рядок
x[,j] — j-ий стовпець
x[,c(1,3)] — задана підмножина стовпців
x["name", ] — рядок з ім'ям name
Фрейми
— стовпець з ім'ям name
x$name — стовпець з ім'ям name
Робота зі змінними
as.array(x), as.data.frame(x), as.numeric(x), as.logical(x), as.complex(x), as.character(x) — перетворення об'єкту до певного типу
is.na(x), is.null(x), is.array(x), is.data.frame(x), is.numeric(x), is.complex(x), is.character(x) — перевірка того, що об'єкт належить до певного типу
length(x) — кількість елементів в x
dim(x) — розмірності об'єкта x
dimnames(x) — імена розмірностей об'єкта x
names(x) — імена об'єкта x
nrow(x) — кількість рядків x
ncol(x) — кількість стовпців x
class(x) — клас об'єкта x
unclass(x) — виділяє атрибут класа у об'єкта x
attr(x,which) — атрибут which об'єкта x
attributes(obj) — перелік атрибутів об'єкта obj
Керування даними
which.max(x) — індекс елемента з максимальним значенням
which.min(x) — індекс елемента з мінімальним значенням
rev(x) — реверсує порядок елементів
sort(x) — сортує елементи об'єкта у порядку збільшення
cut(x,breaks) — розділює вектор на рівні інтервали
match(x, y) — шукає елементи x, які є в y
which(x == a) — вертає порядкові елементи x, які дорівнюють a
na.omit(x) — виключає відсутні значення (NA) об'єкта (у матриці або фреймі виключає відповідний рядок)
na.fail(x) — повертає повідомлення про помилку, якщо об'єкт містить NA
unique(x) — виключає з об'єкта повторювані елементи
table(x) — створює таблицю з кількістю повторювань кожного унікального елемента
subset(x, ...) — вертає підмножину елементів об'єкта, яка відповідає заданій умові
sample(x, size) — вертає випадковий набір розміру size з елементів x
replace(x, list, values) — замінює значення x з індексами з list значеннями values
append(x, values) — додає елементи values до вектору x
Математика
sin(x), cos(x), tan(x), asin(x), acos(x), atan(x), atan2(y, x), log(x), log(x, base), log10(x), exp(x) — елементарні математичні функції
min(x), max(x) — мінімальний та максимальний елементи об'єкта
range(x) — вектор з мінімального та максимального елементів об'єкта
pmin(x, y), pmax(x, y) — вертає вектор з мінімальними (максимальними) значеннями для кожної пари x[i], y[i]
sum(x) — сума елементів об'єкта
prod(x) — добуток (результат множення) елементів об'єкта
diff(x) — вертає вектор з різниць між сусідніми елементами
mean(x) — середнє арифметичне елементів об'єкта
median(x) — медіана об'єкта
weighted.mean(x, w) — середньозважене об'єкта x (w задає ваги)
round(x, n) — округляє x до n десяткових знаків
cumsum(x), cumprod(x), cummin(x), cummax(x) — кумулятивні суми, добутки, мінімуми та максимуми вектора x (i-тий елемент містить статистику по елементам x[1:i])
union(x, y), intersect(x, y), setdiff(x,y), setequal(x,y), is.element(el,set) — операції над множинами: поєднання, перетин, різниця, належність
Re(x), Im(x), Mod(x), Arg(x), Conj(x) — операції над комплексними числами: ціла частина, мнима частина, модуль, аргумент, спряжене число
fft(x), mvfft(x) — швидке перетворення Фур'є
choose(n, k) — кількість комбінацій
rank(x) — ранжує елементи об'єкта
Матриці
%*% — матричне множення
t(x) — транспонована матриця
diag(x) — діагональ матриці
solve(a, b) — вирішує систему рівнянь a %*% x = b
solve(a) — зворотня матриця
colSums, rowSums, colMeans, rowMeans — суми і середні по стовпцям та рядкам
Перебудова даних
apply(X,INDEX,FUN =) — повертає вектор, масив або список значень, отриманих шляхом застосування функції FUN до певних елементів масиву або матриці x; елементи, що мають оброблюватися, вказуються за допомогою аргументу MARGIN;
lapply(X,FUN) — повертає список тієї ж довжини, що і х; при цьому значення в новому списку будуть результатом застосування функції FUN до елементів вихідного об'єкта х
tapply(X,INDEX,FUN =) — застосовує функцію FUN до кожної сукупності значень х, створеної відповідно до рівнів певного фактора; перелік факторів вказується за допомогою аргументу INDEX
by(data,INDEX,FUN) — аналог tapply (), застосовуваний до таблиць даних
merge(a,b) — об'єднує дві таблиці даних (а і b) за загальними стовпцями або рядками
aggregate(x,by,FUN) — розбиває таблицю даних х на окремі набори даних, застосовує до цих наборів певну функцію FUN і повертає результат в зручному для читання форматі
stack(x, ...) — перетворює дані, представлені в об'єкті х у вигляді окремих стовпців, в таблицю даних
unstack(x, ...) — виконує операцію, зворотну дії функції stack()
reshape(x, ...) — перетворює таблицю даних з «широкого формату» (повторні вимірювання будь-якої величини записані в окремих стовпцях таблиці) в таблицю «вузького формату» (повторні вимірювання йдуть одне під одним в межах одного стовпчика)
Дата і час
as.Date(s) — конвертує вектор s в об'єкт класу Date
as.POSIXct(s) — конвертує вектор s в об'єкт класу POSIXct
Рядки
print(x) — виводить на екран x
sprintf(fmt, ...) — форматування тексту в C-style (можна використовувати %s, %.5f тощо)
format(x) — форматує об'єкт x таким чином, щоб він виглядав красиво під час виводу на екран
paste(...) — конвертує вектори в текстові змінні і об'єднує їх в один текстовий вираз
substr(x,start,stop) — отримання підрядка
strsplit(x,split) — розбиває рядок х на підрядки у відповідності до split
grep(pattern,x) (а також grepl, regexpr, gregexpr, regexec) — пошук по регулярному виразу
gsub(pattern,replacement,x) (а також sub) — заміна по регулярному виразу
tolower(x) — привести рядок до нижнього регістру
toupper(x) — привести рядок до верхнього регістру
match(x,table), x %in% table — шукає елементи у векторі table, які співпадають зі значеннями з вектора х
pmatch(x,table) — шукає елементи у векторі table, які частково співпадають зі значеннями з вектора х
nchar(x) — вертає кількість знаків в рядку х
Графіки
plot(x) — графік x
plot(x, y) — графік залежності y от x
hist(x) — гістограма
barplot(x) — стовпчаста діаграма
dotchart(x) — діаграма Кливленда
pie(x) — кругова діаграма
boxplot(x) — графік типу «коробочки с вусами»
sunflowerplot(x, y) — те ж саме, що й plot(), але точки з однаковими координатами зображуються у вигляді «соняшників», кількість пелюсток у яких пропорційна кількості таких точок
coplot(x˜y | z) — графік залежності y от x для кожного інтервалу значень z
interaction.plot(f1, f2, y) — якщо f1 і f2 — фактори, ця фукнкція створить графік з середніми значеннями відповідно до значень f1 (по вісі х) та f2 (по вісі у, різні криві)
matplot(x, y) — графік залежності стовпців y від стовпців x
fourfoldplot(x) — зображує (у вигляді частин окружності) зв'язок між двома бінарними змінними в різних сукупностях
assocplot(x) — графік Кохена-Френдлі
mosaicplot(x) — мозаїчний графік залишків лог-лінійної регресії
pairs(x) — якщо х — матриця або таблиця даних, ця функція зобразить діаграми розсіювання для всіх можливих пар змінних з х
plot.ts(x), ts.plot(x) — зображує часовий ряд
qqnorm(x) — квантилі
qqplot(x, y) — графік залежності квантилів y від квантилів х
contour(x, y, z) — виконує інтерполяцію даних і створює контурний графік
filled.contour(x, y, z) — те ж, що і contour(), але заповнює області між контурами певними кольорами
image(x, y, z) — зображує дані у вигляду квадратів, колір яких визначається значеннями х і у
persp(x, y, z) — те ж, що і image(), але у вигляді трьохвимірного графіка
stars(x) — якщо x — матриця або фрейм, зображує графік у вигляді «зірок» так, що кожен рядок представлений «зіркою», а стовпці визначають довжину променів цих «зірок»
symbols(x, y, ...) — зображує різні символи у відповідності до координат
termplot(mod.obj) — зображує часткові ефекти змінних з регресійної моделі
Окремі елементи графіків
points(x, y) — малювання точок
lines(x, y) — малювання лінії
text(x, y, labels, ...) — додавання текстового надпису
mtext(text, side=3, line=0, ...) — додавання текстового надпису
segments(x0, y0, x1, y1) — додавання відрізка
arrows(x0, y0, x1, y1, angle= 30, code=2) — малювання стрілки
abline(a,b) — малювання нахиленої прямої
abline(h=y) — малювання вертикальної прямої
abline(v=x) — малювання горизонтальної прямої
abline(lm.obj) — малювання регресійної прямої
rect(x1, y1, x2, y2) — малювання прямокутника
polygon(x, y) — малювання багатокутника
legend(x, y, legend) — додавання легенди
title() — додавання назви
axis(side, vect) — додавання осей
rug(x) — малювання засічок на вісі X
locator(n, type = "n", ...) — вертає координати на графіку у відповідь на клік користувача
Гратчасті графіки (Lattice-графіки)
xyplot(y˜x) — графік залежності у від х
barchart(y˜x) — стовпчаста діаграма
dotplot(y˜x) — діаграма Клівленда
densityplot(˜x) — графік щільності розподілу значень х
histogram(˜x) — гістограма значень х
bwplot(y˜x) — графік типу «коробочки с вусами»
qqmath(˜x) — аналог функції qqnorm()
stripplot(y˜x) — аналог функції stripplot(x)
qq(y~x) — зображує квантилі розподілів х і у для візуального порівняння цих розподілів; змінна х має бути числовою, змінна у — числовою, текстовою, або фактором з двома рівнями
splom(~x) — матриця діаграм розсіювання (аналог функції pairs() )
levelplot(z~xy|g1g2) — кольоровий графік значень z, координати яких задані змінними х і у (очевидно, що x, y і z повинні мати однакову довжину); g1, g2 ... (якщо присутні) — фактори або числові змінні, чиї значення автоматично розбиваються на рівномірні відрізки
wireframe(z~xy|g1g2) — функція для побудови тривимірних діаграм розсіювання і площин; z, x і у — числові вектори; g1, g2 ... (якщо присутні) — фактори або числові змінні, чиї значення автоматично розбиваються на рівномірні відрізки
cloud(z˜xy|g1g2) — тривимірна діаграма розсіяння
Оптимізація та підгонка параметрів
optim(par, fn, method = ) — оптимізація загального призначення
nlm(f,p) — мінімізація функції f алгоритмом Ньютона
lm(formula) — підгонка лінійної моделі
glm(formula,family=) — підгонка узагальненої лінійної моделі
nls(formula) — нелінійний метод найменших квадратів
approx(x,y=) — лінійна інтерполяція
spline(x,y=) — інтерполяція кубічними сплайнами
loess(formula) — підгонка поліноміальної поверхні
predict(fit,...) — побудова прогнозів
coef(fit) — розрахункові коефіцієнти
Статистика
sd(x) — стандартне відхилення
var(x) — дисперсія
cor(x) — кореляційна матриця
var(x, y) — коваріація між x та y
cor(x, y) — лінійна кореляція між x та y
aov(formula) — дисперсійний аналіз
anova(fit,...) — дисперсійний аналіз для підігнаних моделей fit
density(x) — ядерні щільності ймовірностей
binom.test() — точний тест простої гіпотези о ймовірності успіху у випробуваннях Бернуллі
pairwise.t.test() — попарні порівняння кількох незалежних або залежних вибірок
prop.test() — перевірка гіпотези про рівність частот певної ознаки в усіх групах, що аналізуються
t.test() — тест Стьюдента
Розподіли
rnorm(n, mean=0, sd=1) — нормальний розподіл
rexp(n, rate=1) — експоненційний розподіл
rgamma(n, shape, scale=1) — гамма-розподіл
rpois(n, lambda) — розподіл Пуассона
rweibull(n, shape, scale=1) — розподіл Вейбулла
rcauchy(n, location=0, scale=1) — розподіл Коші
rbeta(n, shape1, shape2) — бета-розподіл
rt(n, df) — розподіл Стьюдента
rf(n, df1, df2) — розподіл Фішера
rchisq(n, df) — розподіл Пірсона
rbinom(n, size, prob) — біноміальний розподіл
rgeom(n, prob) — геометричний розподіл
rhyper(nn, m, n, k) — гипергеометричний розподіл
rlogis(n, location=0, scale=1) — логістичний розподіл
rlnorm(n, meanlog=0, sdlog=1) — логнормальний розподіл
rnbinom(n, size, prob) — від'ємний біноміальний розподіл
runif(n, min=0, max=1) — рівномірний розподіл
Програмування
Робота з функціями
function(arglist) { expr } — створює функцію користувача
return(value) — возвертає значення
do.call(funname, args) — викликає функцію по імені
Условні оператори
if(cond) expr
if(cond) cons.expr else alt.expr
ifelse(test, yes, no)
Цикли
for(var in seq) expr
while(cond) expr
repeat expr
break — зупинка цикла