 |
||||
|
← |
Д. Шабанов, М. Кравченко. «Статистичний оракул»: аналіз даних в зоології та екології |
→ |
||
|
Фундамент: канон збору первинних даних та використовувані в курсі датафреми |
||||
|
«Статистичний оракул»-01 |
«Статистичний оракул»-03 |
|||
|
2.1 Як має бути організована таблиця з первинними даними дослідження? |
||||
2 Фундамент: канон збору первинних даних та та використовувані в курсі датафрейми
2.1 Як має бути організована таблиця з первинними даними дослідження?
Природничі науки базуються на емпіричному (від грецьк. ἐμπειρία — досвід) дослідженні природи, тобто такому дослідженні, що базується на спостереженні та експерименті. Є в природничих науках і чисто теоретичні (від грецьк. θεωρία — розгляд, дослідження) роботи, пов'язані з внутрішнім розвитком певної моделі, але такі роботи є вторинними, вони — наслідки аналізу емпіричних, первинних даних. Відкіля беруться ці дані? Їх збирають у ході досліджень. Таким чином, збір емпіричних даних є основою усіх природничих наук, у тому числі — біології. Дуже важливо навчитися збирати ці дані таким чином, щоб не обмежити можливості роботи з ними надалі.
Найчастіше за все емпіричні дані збираються або у числовій формі, або у формі, що з часом може бути переведена у числову. Існує точка зору, що там, де нема математики, нема й природничої науки. Скоріше за все, можна уявити собі роботу, в основі якої нема математики, але це, звісно, має бути рідкісний випадок. Головна проблема полягає в тому, що дослідник має впевнитися, що його досвід відбиває загальні закономірності. Ви перегорнули листок і побачили на його нижньому боці гусеницю. Це універсальний досвід чи ні? Перегорнули наступний листок, а під ним — жаба. Скоріше за все, щоб встановити, що ховається під такими листками, слід перегорнути певну їх кількість та зареєструвати, чи було під ними щось, а якщо було — що саме.
Важливіша проблема емпіричного дослідження — наскільки отриманий у ньому досвід є універсальним, наскільки на нього можна спиратися в інших випадках. Інакше кажучи — наскільки достовірним (таким, що заслуговує на довіру, є достойним віри) є отриманий в цьому досвіді результат.
Ви отримали певні емпіричні дані. Що з ними робити? Запам'ятати? Це рішення не є надійним. Наша пам'ять є вибірковою, на наші спогади впливає наше ставлення до того, що ми намагалися запам'ятати. Пам'ять втрачає одне та підмінює інше... Записати на папері? Це вже непогане рішення. Але воно має відповідати певним вимогам. Записувати кожен наступний результат слід відразу, як тільки він отриманий. Записи мають робитися однаково, незалежно від того, якими вони є (наприклад, подобається результат досліднику або ні). Папір (чи інший носій), на якому збережено результати емпіричного дослідження, перетворюється на важливий документ. Він має бути збереженим, і він не має редагуватися з часом! Тому зазвичай первинні записи роблять у лабораторному журналі, де побудована певна таблиця для збереження даних.
Дуже корисно зберігати первинні дані й в інших формах. Це можуть бути фотографії, аудіозаписи, роздруки показників приладів тощо. Це має стати не заміною записів у лабораторному журналі, а їх доповненням! До речі, дуже корисним буває після заповнення сторінки лабораторного журналу сфотографувати її та розмістити таку цифрову фотографію, припустимо, десь у хмарному середовищі...
У сучасному світі досить часто первинні записи роблять не у паперовому журналі, а відразу у цифровому вигляді — у файлі (найчастіше — електронних таблиць, таких як Excel, Calc, Google Sheets). У такому разі з таким файлом слід поводитися як з паперовим лабораторним журналом — зберігати необмежений час, не редагувати наявні записи. Це — носій первинних даних, що зберігає слід важливішого етапу дослідження: дослідник поставив певне питання природі, отримав відповідь та зберіг її! Цей файл і є таблицею для збору емпіричних даних, базою даних, що створюється під час дослідження.
Інший варіант організації роботи — коли первинні дані збираються в лабораторний журнал (або ж на паперові бланки, з якими дослідник працює у польових умовах), а далі переносяться до файлу-таблиці. У такому разі слід зберігати і паперові первинні документи, і первинний файл. Вони мають бути організовані однаково, щоб зменшити ймовірність помилок під час перенесення (і зберігати їх треба для того, щоб такі помилки можна було знайти).
Досвід роботи зі студентами та дослідниками свідчить, що дуже часто великі проблеми у роботі пов'язані з тим, що таблиця для збору первинних даних емпіричного дослідження побудована неправильно. На те, як правильно організовувати збір та збереження первинних даних, вплинуло багато резонів. Деякі з них мають історичні пояснення, деякі — пов'язані з особливостями самого статистичного аналізу. На початку курсу нема сенсу детально аналізувати усі ці резони; набагато краще повідомити їх у формі певного канону. У такому випадку слово «канон» ми розуміємо, як чітку сукупність правил. Звісно, у разі потреби можна відступати від канонічної організації даних, але ця новація має право на життя лише в тому випадку, коли для неї є достатні підстави. Раніше наведене нижче канонічні вимоги ми називали «заповідями», але з часом відмовилися від такої метафори. Порушення заповідей можна розглядати як гріх; на відміну від вимог заповідей, коли це потрібно внаслідок вагомих причин, від канону можна відступати. Втім, у більшості випадків слід просто слідувати канону.
Наведемо один приклад. Канон вимагає, щоб у таблиці з первинними даними рядки відповідали окремим об'єктам, спостереженням, вимірам тощо, а стовпці — ознакам. Можна було зробити навпаки? Можна! У деяких видах аналізу навіть доводиться транспонувати (обмінювати місцями рядки та стовпці) таку таблицю. Але збирають дані саме так. Крім іншого — тому, що усі (хто розуміє) роблять саме так. А роблять вони так тому, що це відповідає логіці роботи з лабораторним журналом. У європейській культурі записи роблять по рядках, а не по стовпцях. Окреме спостереження — окремий рядок, а стовпці відбивають те, що слід враховувати, щоб далі працювати з цим спостереженням. Файл даних має бути організованим так само як сторінка лабораторного журналу, щоб зменшити ймовірність помилок під час перенесення даних.
Будь ласка, зробіть так, щоб ваші уявлення про організацію первинних даних (і файлів для аналізу) відповідали цьому канону за замовченням, by default!
Канон побудови таблиці для збору первинних даних:
1. Збір первинних даних («відповідей природи» досліднику) — наслідок необхідності отримання відповіді на певне питання!
2. При побудові таблиці для даних, слід розуміти, як у разі успіху дослідження буде отримана відповідь на початкове питання!
3. Відповідь на початкове питання — не лише опис результату («того, що вийшло»), а й визначення його статистичної значущості!
4. Статистична значущість результату — ймовірність, що він виник внаслідок випадковості при формуванні дослідженої вибірки!
5. В емпіричних даних є відповіді на ще не поставлені й навіть ще не усвідомлені питання, їх слід зберігати без терміну давності!
6. Первинні дані слід дублювати у різних формах (паперовий лабораторний журнал, бланки, файли, фото записів...)!
7. Типово: на папері та в електронних таблицях — збір даних, створення таблиці; аналіз — у спеціальних програмах!
8. Перенесення, перекодування, реорганізація даних — джерело нових помилок; слід зберігати початковий варіант!
9. Описуються не усі можливі об'єкти? Продумати, обрати, описати та здійснити рандомізацію (випадковий вибір)!
10. Рядки таблиці — окремі об'єкти чи незалежні спостереження, стовпці — ознаки; у комірці — стан ознаки у даного об'єкта!
11. Весь масив даних дослідження — в одній таблиці! Не використовувані в аналізі рядки можна позначити в певному стовпці!
12. У кожному стовпці — однотипні дані, в однакових одиницях, одного формату, однаково виміряні!
13. Усі однотипні дані, в однакових одиницях, одного формату, однаково виміряні — в одному стовпці!
14. Група, до якої належить об'єкт чи спостереження, задається як окрема ознака (а не положенням запису на листі чи в таблиці)!
15. У кожному рядку — усі ознаки (у певних стовпцях), що задають унікальність спостереження (щоб можна було сортувати)!
16. Для кожної ознаки слід розуміти її тип, спосіб визначення або вимірювання, кодування, формат, точність запису тощо!
17. Кількісні ознаки: розуміти, вони мірні (=безперервні, метричні), або рахункові (=дискретні) чи порядкові (=ранги)!
18. Якісні ознаки: розуміти, вони альтернативні («є — нема») або множинні («так, сяк, або етак»)!
19. Якщо первинні дані не символьні (фотографії тощо), окремий стовпчик — посилання на них у «хмарному» сховищі!
20. У кожній комірці — одна певна ознака (а не, припустимо, дві різні, як-от довгота та широта)!
21. «0» — це певне число; відсутність даних — пуста комірка (у програмах може позначатися як NA, «not applicable»)!
22. Порядок стовпців слід узгодити з порядком їх визначення; після емпіричних даних можна розмістити розрахункові!
23. В електронних таблицях і статистичних програмах розрахунки — формулами (можна повторити або виправити)!
24. Назви ознак та їхні стани — бажано латиницею (менше проблем) + якнайдетальніші пояснення для себе та інших!
25. Назви файлів з первинними даними — наочні, відразу зрозумілі; місця їх збереження — передбачувані, зрозуміло підписані!
26. Життя дослідника спростить журнал або файл, де буде розписана методика, усі етапи роботи та усе незвичне у її ході!
27. Перевірка якості даних — візуалізація їх розподілу; діаграма розсіювання покаже викиди та помилки при наборі!
28. Після отримання першого фрагменту бази даних — провести пробний аналіз і виправити недоліки організації дослідження!
Після первинного формулювання цього канону його автор запросив допомоги від колективного розуму. Завдяки порадам від кваліфікованих Facebook-друзів вимоги цього канону вдалося суттєво покращити. Особливу вдячність автори висловлюють професору Олександру Жукову за важливу допомогу.
Таблиця, що відповідає вимогам наведеного канону, може виглядати, наприклад, так, як показано нижче. Рядки — окремі спостереження, стовпці — ознаки. У кожній комірці — стан ознаки, що відповідає стовпцю, для певного спостереження (рядка).

Рис. 2.1.1. Фрагмент умовної таблиці з первинними даними
Одна зі складнощей — що є об'єктом, окремим спостереженням (вимога № 10). Припустимо, ми порівнюємо довжину певної кількості листків з одного дерева... Що є спостереженням: окреме дерево чи довжина окремого листка? Звісно, довжина листка, метрична ознака (вимога № 17). А те, з якого дерева цей листок — це вже групова ознака (вимога № 14). А вид дерева, його висота чи його розташування — ще ознаки (вимога № 15). Для усіх лістків з одного дерева стан цих ознак буде однаковим (в електронних таблицях такі комірки заповнити неважко, хоча слід уважно спостерігати за тим, щоб не помилитися під час їх заповнення). А, припустимо, висота, на якій був розташований листок — ознака, стан якої може відрізнятися для різних листків з одного дерева. А якщо ми для аналізу використаємо не усі дерева, листки з яких ми вимірювали, а лише деякі, ми створимо ще один стопбчик, де укажемо, розглядається це дерево у даному аналізі, або ж ні (вимога № 11).
2.2 Файл-приклад PelophylaxExamples.RData
У подальшому викладі особливості роботи програм будуть пояснюватися переважно з використанням файлів, що відбивають результати справжніх досліджень. Одним з таких файлів є таблиця даних PelophylaxExamples (табл. 2.4.1). Багато матеріалів у даному підручнику стосуються роботи саме з цією базою. Її можна отримати одним із трьох способів. По-перше. її можна завантажити (PelophylaxExamples.csv) або отримати у автора даного тексту. Доступний для завантаження файл має формат .csv (Comma-Separated Values); це один з поширених форматів для переносу даних між різними програмами. Фактично це текстовий формат, де наведено табличні дані. Кожне наступне значення відділяється від попереднього розділювачем (у типовому випадку — комами, у пропонованому файлі — крапками з комами). Якщо поля таблиці розділені комами, їх неможливо використовувати у якості десяткових розділювачів (нагадуємо, що у більшості розвинених країн у якості десяткового розділювача використовують коми).
У файлі використаний фрагмент даних, отриманих О. В. Коршуновим при підготовці дисертації на здобуття наукового ступеня кандидата біологічних наук (автори щиро вдячні О. В. Коршунову за дозвіл використовувати результати його роботи). В оригінальному файлі містився опис кількохсот жаб за 16 морфометричними ознаками; в обраному фрагменті залишено 57 жаб і наведені дані про мінливість у них 7 морфометричних ознак.
При використанні електронної версії конспекту наведені нижче дані можна перенести з вікна браузера. файлу Word чи .pdf в необхідну програму. Якщо ви користуєтеся R, можна просто ввести усі дані та створити з них датафрейм. Це нескладно. Перш за все, ви можете скопіювати в електронній формі усі використані у файлі-прикладі дані і додати їх у ваш R-скрипт.
Place <- c("Krasnocuts`k", "Chernetchina", "Chernetchina", "Chernetchina", "Chernetchina", "Izbickoe", "DobritzkiyYar", "DobritzkiyYar", "KreydyanaDacha", "KreydyanaDacha", "Verbunivs`kaDacha", "Verbunivs`kaDacha", "Verbunivs`kaDacha", "Zamulivka", "Zamulivka", "ChervoniyShahtar", "Sharivka", "Sharivka", "Lipci", "Gaydary", "DobritzkiyYar", "DobritzkiyYar", "VelykaGomol`sha", "SuhaGomol`sha", "KreydyanaDacha", "Verbunivs`kaDacha", "Pechenizhsk`iyRibhoz", "Eschar", "Balakliya", "Gatishe", "Gaydary", "Gaydary", "Gaydary", "Gaydary", "Gaydary", "Gaydary", "DobritzkiyYar", "SuhaGomol`sha", "KreydyanaDacha", "KreydyanaDacha", "Verbunivs`kaDacha", "Verbunivs`kaDacha", "Balakliya", "Gorodnee", "Gubarivka", "Lipci", "Martova", "Pechenigy", "SuhaGomol`sha", "ChervonaGusarivka", "ChervonaGusarivka", "Vesele", "Petropillya", "Eschar", "Balakliya", "Zamulivka", "Liman")
East <- c(35.16, 35.13, 35.13, 35.13, 35.13, 36.73, 36.31, 36.31, 36.80, 36.80, 36.89, 36.89, 36.89, 36.46, 36.46, 37.03, 35.47, 35.47, 36.38, 36.33, 36.31, 36.31, 36.27, 36.34, 36.80, 36.89, 36.59, 36.35, 36.48, 36.52, 36.33, 36.33, 36.33, 36.33, 36.33, 36.33, 36.31, 36.34, 36.80, 36.80, 36.89, 36.89, 36.48, 35.14, 35.35, 36.38, 36.96, 36.99, 36.34, 36.86, 36.86, 37.19, 37.13, 36.35, 36.48, 36.46, 36.32)
North <- c(50.07, 50.05, 50.05, 50.05, 50.05, 50.20, 49.56, 49.56, 49.43, 49.43, 49.42, 49.42, 49.42, 50.08, 50.08, 49.18, 50.04, 50.04, 50.21, 49.62, 49.56, 49.56, 49.57, 49.54, 49.43, 49.42, 49.52, 49.47, 49.27, 50.18, 49.62, 49.62, 49.62, 49.62, 49.62, 49.62, 49.56, 49.54, 49.43, 49.43, 49.42, 49.42, 49.27, 50.05, 50.16, 50.21, 49.93, 49.89, 49.54, 49.41, 49.41, 49.40, 49.09, 49.47, 49.27, 50.08, 49.35)
Basin <- c("Dnipro", "Dnipro", "Dnipro", "Dnipro", "Dnipro", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Dnipro", "Dnipro", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Dnipro", "Dnipro", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don", "Don")
Basin <- factor(Basin, levels = c("Dnipro", "Don"))
Sex <- c("female", "female", "female", "male", "female", "female", "male", "female", "male", "female", "male", "male", "female", "female", "female", "female", "male", "female", "male", "female", "female", "male", "male", "female", "male", "female", "male", "male", "female", "female", "male", "male", "male", "female", "male", "female", "female", "female", "male", "male", "female", "female", "male", "male", "male", "female", "female", "female", "female", "male", "female", "female", "female", "male", "male", "male", "male")
Sex <- factor(Sex, levels = c("female", "male"))
DNA <- c(14.03, 13.95, 13.99, 13.95, 14.02, 21.83, 21.43, 21.67, 21.62, 21.61, 21.61, 21.64, 21.50, 21.43, 21.60, 22.03, 14.94, 14.91, 14.86, 14.88, 14.95, 14.91, 14.80, 15.09, 14.79, 14.91, 14.72, 14.91, 14.85, 14.91, 22.97, 22.64, 22.98, 22.80, 22.81, 22.79, 22.60, 22.79, 22.74, 22.73, 22.81, 22.85, 22.85, 16.13, 16.27, 16.00, 16.18, 16.22, 15.99, 16.01, 16.07, 16.11, 16.01, 16.03, 15.92, 16.08, 16.20)
Genotype <- c("LL", "LL", "LL", "LL", "LL", "LLR", "LLR", "LLR", "LLR", "LLR", "LLR", "LLR", "LLR", "LLR", "LLR", "LLR", "LR", "LR", "LR", "LR", "LR", "LR", "LR", "LR", "LR", "LR", "LR", "LR", "LR", "LR", "LRR", "LRR", "LRR", "LRR", "LRR", "LRR", "LRR", "LRR", "LRR", "LRR", "LRR", "LRR", "LRR", "RR", "RR", "RR", "RR", "RR", "RR", "RR", "RR", "RR", "RR", "RR", "RR", "RR", "RR")
levels(Genotype) <- c("LL", "LLR", "LR", "LRR", "RR")
Lc <- c(60.3, 56.2, 59.2, 59.5, 60.2, 62.5, 58.9, 65.8, 52.8, 55.7, 52.9, 57.4, 61.6, 76.7, 80.0, 47.9, 65.9, 69.1, 66.8, 79.1, 70.7, 71.4, 55.3, 87.7, 65.0, 54.3, 66.2, 56.1, 64.1, 56.9, 58.8, 65.3, 65.5, 67.7, 69.1, 74.2, 71.5, 50.4, 56.4, 75.5, 61.8, 68.9, 72.1, 70.6, 50.8, 70.1, 82.5, 53.7, 53.5, 52.1, 54.2, 69.3, 71.0, 68.6, 79.2, 93.0, 65.6)
Ltc <- c(19.4, 18.7, 19.5, 19.9, 21.8, 22.1, 21.6, 24.1, 19.6, 20.0, 19.2, 19.9, 23.0, 24.0, 26.2, 18.9, 20.8, 22.7, 22.6, 29.9, 22.9, 24.4, 21.0, 33.8, 22.5, 19.0, 25.2, 20.9, 26.8, 20.1, 20.6, 21.5, 22.1, 29.4, 22.6, 25.5, 22.0, 20.3, 19.2, 26.8, 21.2, 24.8, 27.8, 26.6, 19.1, 27.0, 31.5, 18.9, 20.0, 18.6, 19.3, 24.7, 25.6, 26.8, 26.2, 26.5, 21.9)
Fm <- c(26.4, 26.6, 28.1, 28.5, 28.7, 30.3, 29.0, 30.6, 25.7, 25.1, 25.8, 26.3, 31.6, 34.9, 38.9, 23.8, 30.2, 35.9, 33.5, 38.1, 33.4, 35.6, 26.2, 37.6, 32.0, 26.6, 32.1, 27.3, 31.7, 26.0, 28.8, 31.5, 32.8, 33.8, 33.0, 35.2, 35.3, 23.1, 28.3, 41.1, 28.8, 31.6, 35.9, 32.6, 25.9, 36.0, 42.3, 25.9, 26.5, 24.3, 26.2, 34.1, 33.9, 33.6, 34.0, 46.2, 35.2)
Ti <- c(25.5, 24.9, 26.1, 28.6, 28.1, 29.2, 27.7, 30.4, 24.6, 25.7, 26.2, 26.7, 29.8, 34.6, 37.6, 24.6, 30.0, 34.9, 32.8, 39.4, 33.2, 34.1, 28.0, 42.3, 31.9, 27.3, 32.5, 28.5, 32.3, 28.1, 28.9, 31.9, 34.5, 36.4, 33.4, 35.6, 34.4, 24.8, 29.3, 37.2, 30.2, 34.1, 35.9, 36.2, 27.7, 37.6, 44.3, 27.3, 28.1, 26.7, 28.2, 36.2, 37.1, 36.1, 35.7, 46.1, 33.7)
Dp <- c(7.6, 6.2, 7.9, 7.5, 8.0, 8.3, 7.7, 9.6, 6.6, 6.7, 7.7, 7.8, 9.1, 9.5, 11.6, 6.5, 8.4, 9.8, 8.6, 11.6, 9.7, 9.3, 8.5, 13.9, 9.0, 7.9, 9.2, 7.7, 9.3, 9.0, 9.1, 8.2, 9.2, 10.8, 9.2, 10.7, 10.3, 6.3, 7.7, 10.6, 9.4, 10.4, 10.4, 9.7, 6.6, 10.6, 12.4, 7.2, 7.8, 6.5, 7.1, 10.4, 9.9, 10.3, 9.3, 13.8, 9.0)
Ci <- c(4.2, 4.1, 3.7, 3.8, 4.5, 3.7, 3.7, 3.4, 3.1, 3.3, 3.5, 3.8, 3.9, 4.4, 4.9, 2.7, 4.8, 4.8, 4.4, 4.7, 4.3, 5.3, 2.8, 4.7, 3.8, 3.3, 4.3, 3.7, 4.1, 3.6, 3.5, 3.8, 4.5, 4.3, 4.0, 4.0, 4.1, 3.1, 3.0, 4.2, 3.2, 3.7, 4.7, 3.7, 2.7, 3.0, 4.9, 2.8, 3.2, 2.8, 2.7, 3.2, 3.4, 3.8, 3.2, 3.1, 3.6)
Cs <- c(11.9, 15.2, 13.2, 11.4, 15.8, 14.5, 15.2, 17.0, 12.7, 14.3, 12.8, 14.6, 15.5, 16.0, 19.6, 11.8, 16.6, 17.6, 17.5, 23.3, 15.0, 18.1, 14.4, 22.7, 16.4, 12.7, 18.6, 16.1, 17.3, 15.6, 13.7, 15.1, 15.9, 18.1, 16.7, 17.4, 15.5, 11.7, 13.9, 18.9, 14.5, 17.9, 19.6, 18.7, 12.9, 17.8, 24.0, 11.9, 14.5, 12.4, 12.9, 17.4, 17.7, 19.7, 17.2, 20.2, 15.4)
PE <- data.frame(Sex, Genotype, Lc, Ltc, Fm, Ti, Dp, Ci, Cs)
row.names(PE) <- c("LL_f_603", "LL_f_562", "LL_f_592", "LL_m_595", "LL_f_602", "LLR_f_625", "LLR_m_589", "LLR_f_658", "LLR_m_528", "LLR_f_557", "LLR_m_529", "LLR_m_574", "LLR_f_616", "LLR_f_767", "LLR_f_800", "LLR_f_479", "LR_m_659", "LR_f_691", "LR_m_668", "LR_f_791", "LR_f_707", "LR_m_714", "LR_m_553", "LR_f_877", "LR_m_650", "LR_f_543", "LR_m_662", "LR_m_561", "LR_f_641", "LR_f_569", "LRR_m_588", "LRR_m_653", "LRR_m_655", "LRR_f_677", "LRR_m_691", "LRR_f_742", "LRR_f_715", "LRR_f_504", "LRR_m_564", "LRR_m_755", "LRR_f_618", "LRR_f_689", "LRR_m_721", "RR_m_706", "RR_m_508", "RR_f_701", "RR_f_825", "RR_f_537", "RR_f_535", "RR_m_521", "RR_f_542", "RR_f_693", "RR_f_710", "RR_m_686", "RR_m_792", "RR_m_930", "RR_m_656")Тепер можна створити з цих векторів датафрейм. Коди особин перетворимо на імена рядків.
PE <- data.frame(Sex, Genotype, Lc, Ltc, Fm, Ti, Dp, Ci, Cs)
row.names(PE) <- c("LL_f_603", "LL_f_562", "LL_f_592", "LL_m_595", "LL_f_602", "LLR_f_625", "LLR_m_589", "LLR_f_658", "LLR_m_528", "LLR_f_557", "LLR_m_529", "LLR_m_574", "LLR_f_616", "LLR_f_767", "LLR_f_800", "LLR_f_479", "LR_m_659", "LR_f_691", "LR_m_668", "LR_f_791", "LR_f_707", "LR_m_714", "LR_m_553", "LR_f_877", "LR_m_650", "LR_f_543", "LR_m_662", "LR_m_561", "LR_f_641", "LR_f_569", "LRR_m_588", "LRR_m_653", "LRR_m_655", "LRR_f_677", "LRR_m_691", "LRR_f_742", "LRR_f_715", "LRR_f_504", "LRR_m_564", "LRR_m_755", "LRR_f_618", "LRR_f_689", "LRR_m_721", "RR_m_706", "RR_m_508", "RR_f_701", "RR_f_825", "RR_f_537", "RR_f_535", "RR_m_521", "RR_f_542", "RR_f_693", "RR_f_710", "RR_m_686", "RR_m_792", "RR_m_930", "RR_m_656")Цей датафрейм можна зберегти, а далі, за необхідності, читати цей файл (і збереження та читання даних, і необхідне для цього визначення робочої директорії описано у наступному розділі). Можна зробити й простіше — просто починати усі скрипти з наведених команд, створюючи необхідний датафрейм PE.
Ознаки перелічених особин, використані у файлі, є такими:
Place — Місце походження
East — Східна довгота
North — Північна широта
Basin — Водозбірний басейн (Dnipro, Don)
Sex — Стать (female, male)
DNA — Маса геному (пг)
Genotyp — Генотип (LL, LLR, LR, LRR, RR)
Lс — (L.) — Longitudo corporis — Довжина тіла
Ltc — (Lt.c.) — Latitudo capitis — Ширина голови
Fm — (F.) — Longitudo femoris — Довжина стегна
Tі — (T.) — Longitudo tibiae — Довжина гомілки
Dp — (D.p.) — Digitus primus — Довжина 1-го (внутрішнього) пальця задньої кінцівки
Ci — (C.i.) — Callus internus — Довжина внутрішнього п'яткового горбку
Cs — (C.s.) — Longitudo crus secondarius — Довжина додаткової гомілки
Всі описані у цій базі особини належать до гібридогенного комплексу зелених жаб, Pelophylax esculentus complex. Це два батьківських види, ставкова жаба Pelophylax lessonae (Camerano, 1882) і озерна жаба, P. ridibundus (Pallas, 1771), а також їх диплоїдні і триплоїдні гібриди, звані їстівними жабами, P. esculentus (Linnaeus, 1758). Триплоїдні гібриди P. esculentus представлені двома формами, що відрізняються за складом геномів в генотипі. Відтворення гібридів пов'язано з феноменом геміклональной спадковості. Перелічені форми жаб у різному складі можуть утворювати геміклональні популяційні системи (ГПС), де рід час спільного відтворення передаються як клональні, так і рекомбінантні геноми (детальніше — в огляді гібридогенного комплексу зелених жаб).
Батьківські види і гібриди мають певні зовнішні особливості, які, однак, не дозволяють чітко відрізняти їх один від одного. Один з методів доказової ідентифікації різних форм зелених жаб полягає у використанні проточної ДНК-цитометрії. Клітини жаб з струмом рідини проходять через ультрафіолетовий детектор. Вони опромінюються ультрафіолетовим випромінюванням на тій довжині хвилі, на який ДНК поглинає випромінення, а потім на тій довжині, на якій збуджена ДНК випромінює енергію, реєструється інтенсивність флуоресценції клітини. Порівнюючи клітини досліджуваних особин з реперними клітинами (наприклад, трав'яної жаби, Rana temporaria), що мають точно відому масу ДНК у кожній клітині, можна визначити масу ДНК в досліджуваних клітинах. Ця маса вимірюється в пікограмах, пг. Оскільки відомо, що геном P. lessonae має масу близько 7 пг, а геном P. ridibundus — 8 пг, за масою клітинної ДНК можна визначити, які геноми входять в генотип даної особини.
У прикладі PelophylaxExamples містяться дані про жаб з 5 різними генотипами. Геном P. lessonae позначено як L, геном P. ridibundus — як R, і ці 5 форм — це LL, LLR, LR, LRR і RR. Всі ці форми зустрічаються в Харківській області.
У базі PelophylaxExamples рядкам (Cases, rows, спостереженням) відповідають окремі особини, а стовпцям (Variables, columns, змінним) — їхні ознаки. Характеристика кожної особини включає в себе місце збору, його координати, а також інформації про належність точки здору або до водозбірного басейну Дніпра (захід і північний захід Харківської області) або Дона (тобто Сіверського Дінця; більша частина території області). Крім того, для кожної жаби вказується її стать. У файлі наведено дані про статевозрілих жаб.
Вимірювання морфометричних ознак проводилося на фіксованих жабах за допомогою штангенциркуля; дані вимірювалися з точністю до 0,1 мм; результати вимірів вказані у мм. Найістотнішою з цих ознак є довжина тіла. Всі інші ознаки можуть використовуватися як у вигляді абсолютних значень, так і у вигляді пропорцій (відношення даної ознаки до довжини тіла). Крім того, для тих чи інших цілей можуть обчислюватися індекси — комплексні ознаки, які обчислюються як певні комбінації вихідних морфометрических ознак. Строго кажучи, пропорції (відносини промірів до довжини тіла) теж є індексами, але в цілях зручності ці поняття простіше звузити так, як це запропоновано в даному абзаці.
Таблиця 2.2.1. Дані, включені в файл PelophylaxExamples: статевозрілі зелені жаби з Харківської області (невипадкова вибірка)
| Place | East | North | Basin | Sex | DNA | Genotypе | Lc | Ltc | Fm | Ti | Dp | Ci | Cs | |
| LL_f_603 | Krasnocuts`k | 35.16 | 50.07 | Dnipro | female | 14.03 | LL | 60.3 | 19.4 | 26.4 | 25.5 | 7.6 | 4.2 | 11.9 |
| LL_f_562 | Chernetchina | 35.13 | 50.05 | Dnipro | female | 13.95 | LL | 56.2 | 18.7 | 26.6 | 24.9 | 6.2 | 4.1 | 15.2 |
| LL_f_592 | Chernetchina | 35.13 | 50.05 | Dnipro | female | 13.99 | LL | 59.2 | 19.5 | 28.1 | 26.1 | 7.9 | 3.7 | 13.2 |
| LL_m_595 | Chernetchina | 35.13 | 50.05 | Dnipro | male | 13.95 | LL | 59.5 | 19.9 | 28.5 | 28.6 | 7.5 | 3.8 | 11.4 |
| LL_f_602 | Chernetchina | 35.13 | 50.05 | Dnipro | female | 14.02 | LL | 60.2 | 21.8 | 28.7 | 28.1 | 8.0 | 4.5 | 15.8 |
| LLR_f_625 | Izbickoe | 36.73 | 50.20 | Don | female | 21.83 | LLR | 62.5 | 22.1 | 30.3 | 29.2 | 8.3 | 3.7 | 14.5 |
| LLR_m_589 | DobritzkiyYar | 36.31 | 49.56 | Don | male | 21.43 | LLR | 58.9 | 21.6 | 29.0 | 27.7 | 7.7 | 3.7 | 15.2 |
| LLR_f_658 | DobritzkiyYar | 36.31 | 49.56 | Don | female | 21.67 | LLR | 65.8 | 24.1 | 30.6 | 30.4 | 9.6 | 3.4 | 17.0 |
| LLR_m_528 | KreydyanaDacha | 36.80 | 49.43 | Don | male | 21.62 | LLR | 52.8 | 19.6 | 25.7 | 24.6 | 6.6 | 3.1 | 12.7 |
| LLR_f_557 | KreydyanaDacha | 36.80 | 49.43 | Don | female | 21.61 | LLR | 55.7 | 20.0 | 25.1 | 25.7 | 6.7 | 3.3 | 14.3 |
| LLR_m_529 | Verbunivs`kaDacha | 36.89 | 49.42 | Don | male | 21.61 | LLR | 52.9 | 19.2 | 25.8 | 26.2 | 7.7 | 3.5 | 12.8 |
| LLR_m_574 | Verbunivs`kaDacha | 36.89 | 49.42 | Don | male | 21.64 | LLR | 57.4 | 199 | 26.3 | 26.7 | 7.8 | 3.8 | 14.6 |
| LLR_f_616 | Verbunivs`kaDacha | 36.89 | 49.42 | Don | female | 21.50 | LLR | 61.6 | 23.0 | 31.6 | 29.8 | 9.1 | 3.9 | 15.5 |
| LLR_f_767 | Zamulivka | 36.46 | 50.08 | Don | female | 21.43 | LLR | 76.7 | 24.0 | 34.9 | 34.6 | 9.5 | 4.4 | 16.0 |
| LLR_f_800 | Zamulivka | 36.46 | 50.08 | Don | female | 21.60 | LLR | 80.0 | 26.2 | 38.9 | 37.6 | 11.6 | 4.9 | 19.6 |
| LLR_f_479 | ChervoniyShahtar | 37.03 | 49.18 | Don | female | 22.03 | LLR | 47.9 | 18.9 | 23.8 | 24.6 | 6.5 | 2.7 | 11.8 |
| LR_m_659 | Sharivka | 35.47 | 50.04 | Dnipro | male | 14.94 | LR | 65.9 | 20.8 | 30.2 | 30.0 | 8.4 | 4.8 | 16.6 |
| LR_f_691 | Sharivka | 35.47 | 50.04 | Dnipro | female | 14.91 | LR | 69.1 | 22.7 | 35.9 | 34.9 | 9.8 | 4.8 | 17.6 |
| LR_m_668 | Lipci | 36.38 | 50.21 | Don | male | 14.86 | LR | 66.8 | 22.6 | 33.5 | 32.8 | 8.6 | 4.4 | 17.5 |
| LR_f_791 | Gaydary | 36.33 | 49.62 | Don | female | 14.88 | LR | 79.1 | 29.9 | 38.1 | 39.4 | 11.6 | 4.7 | 23.3 |
| LR_f_707 | DobritzkiyYar | 36.31 | 49.56 | Don | female | 14.95 | LR | 70.7 | 22.9 | 33.4 | 33.2 | 9.7 | 4.3 | 15.0 |
| LR_m_714 | DobritzkiyYar | 36.31 | 49.56 | Don | male | 14.91 | LR | 71.4 | 24.4 | 35.6 | 34.1 | 9.3 | 5.3 | 18.1 |
| LR_m_553 | VelykaGomol`sha | 36.27 | 49.57 | Don | male | 14.80 | LR | 55.3 | 21.0 | 26.2 | 28.0 | 8.5 | 2.8 | 14.4 |
| LR_f_877 | SuhaGomol`sha | 36.34 | 49.54 | Don | female | 15.09 | LR | 87.7 | 33.8 | 37.6 | 42.3 | 13.9 | 4.7 | 22.7 |
| LR_m_650 | KreydyanaDacha | 36.80 | 49.43 | Don | male | 14.79 | LR | 65.0 | 22.5 | 32.0 | 31.9 | 9.0 | 3.8 | 16.4 |
| LR_f_543 | Verbunivs`kaDacha | 36.89 | 49.42 | Don | female | 14.91 | LR | 54.3 | 19.0 | 26.6 | 27.3 | 7.9 | 3.3 | 12.7 |
| LR_m_662 | Pechenizhsk`iyRibhoz | 36.59 | 49.52 | Don | male | 14.72 | LR | 66.2 | 25.2 | 32.1 | 32.5 | 9.2 | 4.3 | 18.6 |
| LR_m_561 | Eschar | 36.35 | 49.47 | Don | male | 14.91 | LR | 56.1 | 20.9 | 27.3 | 28.5 | 7.7 | 3.7 | 16.1 |
| LR_f_641 | Balakliya | 36.48 | 49.27 | Don | female | 14.85 | LR | 64.1 | 26.8 | 31.7 | 32.3 | 9.3 | 4.1 | 17.3 |
| LR_f_569 | Gatishe | 36.52 | 50.18 | Don | female | 14.91 | LR | 56.9 | 20.1 | 26.0 | 28.1 | 9.0 | 3.6 | 15.6 |
| LRR_m_588 | Gaydary | 36.33 | 49.62 | Don | male | 22.97 | LRR | 58.8 | 20.6 | 28.8 | 28.9 | 9.1 | 3.5 | 13.7 |
| LRR_m_653 | Gaydary | 36.33 | 49.62 | Don | male | 22.64 | LRR | 65.3 | 21.5 | 31.5 | 31.9 | 8.2 | 3.8 | 15.1 |
| LRR_m_655 | Gaydary | 36.33 | 49.62 | Don | male | 22.98 | LRR | 65.5 | 22.1 | 32.8 | 34.5 | 9.2 | 4.5 | 15.9 |
| LRR_f_677 | Gaydary | 36.33 | 49.62 | Don | female | 22.80 | LRR | 67.7 | 29.4 | 33.8 | 36.4 | 10.8 | 4.3 | 18.1 |
| LRR_m_691 | Gaydary | 36.33 | 49.62 | Don | male | 22.81 | LRR | 69.1 | 22.6 | 33.0 | 33.4 | 9.2 | 4.0 | 16.7 |
| LRR_f_742 | Gaydary | 36.33 | 49.62 | Don | female | 22.79 | LRR | 74.2 | 25.5 | 35.2 | 35.6 | 10.7 | 4.0 | 17.4 |
| LRR_f_715 | DobritzkiyYar | 36.31 | 49.56 | Don | female | 22.60 | LRR | 71.5 | 22.0 | 35.3 | 34.4 | 10.3 | 4.1 | 15.5 |
| LRR_f_504 | SuhaGomol`sha | 36.34 | 49.54 | Don | female | 22.79 | LRR | 50.4 | 20.3 | 23.1 | 24.8 | 6.3 | 3.1 | 11.7 |
| LRR_m_564 | KreydyanaDacha | 36.80 | 49.43 | Don | male | 22.74 | LRR | 56.4 | 19.2 | 28.3 | 29.3 | 7.7 | 3.0 | 13.9 |
| LRR_m_755 | KreydyanaDacha | 36.80 | 49.43 | Don | male | 22.73 | LRR | 75.5 | 26.8 | 41.1 | 37.2 | 10.6 | 4.2 | 18.9 |
| LRR_f_618 | Verbunivs`kaDacha | 36.89 | 49.42 | Don | female | 22.81 | LRR | 61.8 | 21.2 | 28.8 | 30.2 | 9.4 | 3.2 | 14.5 |
| LRR_f_689 | Verbunivs`kaDacha | 36.89 | 49.42 | Don | female | 22.85 | LRR | 68.9 | 24.8 | 31.6 | 34.1 | 10.4 | 3.7 | 17.9 |
| LRR_m_721 | Balakliya | 36.48 | 49.27 | Don | male | 22.85 | LRR | 72.1 | 27.8 | 35.9 | 35.9 | 10.4 | 4.7 | 19.6 |
| RR_m_706 | Gorodnee | 35.14 | 50.05 | Dnipro | male | 16.13 | RR | 70.6 | 26.6 | 32.6 | 36.2 | 9.7 | 3.7 | 18.7 |
| RR_m_508 | Gubarivka | 35.35 | 50.16 | Dnipro | male | 16.27 | RR | 50.8 | 19.1 | 25.9 | 27.7 | 6.6 | 2.7 | 12.9 |
| RR_f_701 | Lipci | 36.38 | 50.21 | Don | female | 16.00 | RR | 70.1 | 27.0 | 36.0 | 37.6 | 10.6 | 3.0 | 17.8 |
| RR_f_825 | Martova | 36.96 | 49.93 | Don | female | 16.18 | RR | 82.5 | 31.5 | 42.3 | 44.3 | 12.4 | 4.9 | 24.0 |
| RR_f_537 | Pechenigy | 36.99 | 49.89 | Don | female | 16.22 | RR | 53.7 | 18.9 | 25.9 | 27.3 | 7.2 | 2.8 | 11.9 |
| RR_f_535 | SuhaGomol`sha | 36.34 | 49.54 | Don | female | 15.99 | RR | 53.5 | 20.0 | 26.5 | 28.1 | 7.8 | 3.2 | 14.5 |
| RR_m_521 | ChervonaGusarivka | 36.86 | 49.41 | Don | male | 16.01 | RR | 52.1 | 18.6 | 24.3 | 26.7 | 6.5 | 2.8 | 12.4 |
| RR_f_542 | ChervonaGusarivka | 36.86 | 49.41 | Don | female | 16.07 | RR | 54.2 | 19.3 | 26.2 | 28.2 | 7.1 | 2.7 | 12.9 |
| RR_f_693 | Vesele | 37.19 | 49.40 | Don | female | 16.11 | RR | 69.3 | 24.7 | 34.1 | 36.2 | 10.4 | 3.2 | 17.4 |
| RR_f_710 | Petropillya | 37.13 | 49.09 | Don | female | 16.01 | RR | 71.0 | 25.6 | 33.9 | 37.1 | 9.9 | 3.4 | 17.7 |
| RR_m_686 | Eschar | 36.35 | 49.47 | Don | male | 16.03 | RR | 68.6 | 26.8 | 33.6 | 36.1 | 10.3 | 3.8 | 19.7 |
| RR_m_792 | Balakliya | 36.48 | 49.27 | Don | male | 15.92 | RR | 79.2 | 26.2 | 34.0 | 35.7 | 9.3 | 3.2 | 17.2 |
| RR_m_930 | Zamulivka | 36.46 | 50.08 | Don | male | 16.08 | RR | 93.0 | 26.5 | 46.2 | 46.1 | 13.8 | 3.1 | 20.2 |
| RR_m_656 | Liman | 36.32 | 49.35 | Don | male | 16.20 | RR | 65.6 | 21.9 | 35.2 | 33.7 | 9.0 | 3.6 | 15.4 |
2.3 Файл-приклад Bufotis_viridis_database.RData
Для розгляду у даному курсі може бути корисною і інша база даних, відносно більша за розміром. Це — частина даних, які були використані в кандидатській дисертації одного з авторів цього підручника (Д.Ш.), яка була захищена у 2004 році. Дисертація була присвячена популяційному різноманіттю зелених (Bufotis viridis) та сірих (Bufo bufo) ропух у Лівобережному лісостепу України. Тут наведено лише ту частину даних, що стосувалася зелених ропух. В базі даних схарактеризовані вибірки ропух, що збиралися на місцях нересту невибірковим (відносно випадково для особин, що перебували на нерестовищах) у останні роки XX сторіччя та перші роки XXI сторіччя. Досліджені особини ропух передані для збереження у Музей природи Харківського національного університету імені В.Н.Каразіна. Місця збору та чисельність вибірок показані на рис. 2.3.1. Зверніть увагу: багато топонімів з часу збору вибірок змінилося; на мапі підписані ті назви, що існували у 2004 році!
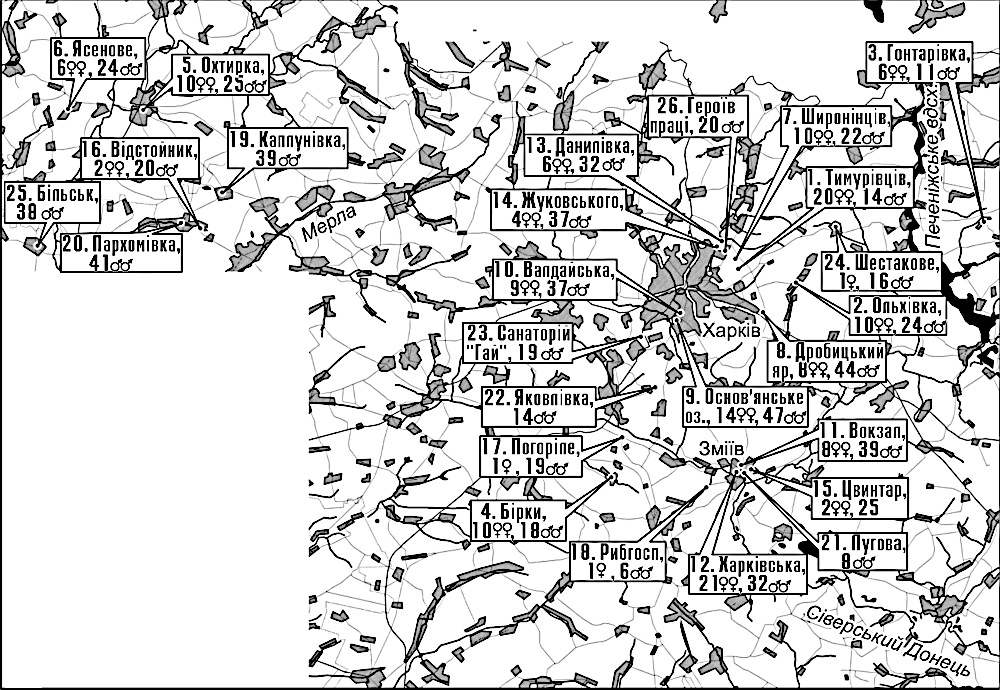
Рис. 2.3.1. Місця збору, номери, умовні назви та чисельність вибірок Bufotis viridis з бази даних Bufotis_viridis_database.RData
Для місць збору вибірок наведені географічні координати (дрібні значення — у десятковому форматі). Ропух описували шляхом заповнення певної паперової форми. В цій формі було передбачено встановлення стану значної кількості морфометричних ознак (табл. 2.3.1), а також альтернативних фенетичних та рангових ознак (табл. 2.3.2). Не усі використані під час опису ознаки виявилися корисними для дослідження різноманіття. У дисертаційному дослідженні було використано методи багатовимірної статистики; переважно використовувалося значення пропорційних ознак (результату поділу метричних ознак, крім першої, на першу, довжину тіла). В наведених таблицях зазначені старі коди, що використовувалися для перелічених ознак в дисертації, яка була захищена у 2004 році; коди були змінені для зручності користування базою даних, а старі коди зазначені на усякий випадок, наприклад, для можливості порівняння результатів з авторефератом захищеної дисертації.
Описану базу даних можна завантажити за посиланням, як це показано на рис. 2.3.2.
Рис. 2.3.2. Завантаження Bufotis_viridis_database.RData
Таблиця 2.3.1. Морфометричні ознаки, за якими були описані зелені ропухи (Bufotis viridis) у датафреймі Bufotis_viridis_database.RData
|
Код |
Ознака |
Код | Ознака | Старий код |
|
L01 |
Довжина тіла |
С01L | ||
|
M02 |
Ширина голови |
P02 | Відносна ширина голови | С02M, С02P |
|
M03 |
Довжина голови |
P03 | Відносна довжина голови | С03M, С03P |
|
M04 |
Довжина ока |
P04 | Відносна довжина ока | С04M, С04P |
|
M05 |
Відстань між повіками |
P05 | Відносна відстань між повіками | С05M, С05P |
|
M06 |
Ширина повіки |
P06 | Відносна ширина повіки | С06M, С06P |
|
M07 |
Відстань від переднього краю ока до ніздрі |
P07 | Відносна відстань від переднього краю ока до ніздрі | С07M, С07P |
|
M08 |
Відстань між ніздрями |
P08 | Відносна відстань між ніздрями | С08M, С08P |
|
M09 |
Відстань від рострума до ніздрі |
P09 | Відносна відстань від рострума до ніздрі | С09M, С09P |
|
M10 |
Відстань від рострума до кута щелепи |
P10 | Відносна відстань від рострума до кута щелепи | С10M, С10P |
|
M11 |
Відстань від ока до барабанної перетинки |
P11 | Відносна відстань від ока до барабанної перетинки | С11M, С11P |
|
M12 |
Вертикальний діаметр барабанної перетинки |
P12 | Відносний вертикальний діаметр барабанної перетинки | С12M, С12P |
|
M13 |
Горизонтальний діаметр барабанної перетинки |
P13 | Відносний оризонтальний діаметр барабанної перетинки | С13M, С13P |
|
M14 |
Відстань від рострума до лівої надлопаткової залози |
P14 | Відносна відстань від рострума до лівої надлопаткової залози | С14M, С14P |
|
M15 |
Відстань від рострума до правої надлопаткової залози |
P15 | Відносна відстань від рострума до правої надлопаткової залози | С15M, С15P |
|
M16 |
Відстань між передніми кінцями надлопаткових залоз |
P16 | Відносна відстань між передніми кінцями надлопаткових залоз | С16M, С16P |
|
M17 |
Відстань між задніми кінцями надлопаткових залоз |
P17 | Відносна відстань між задніми кінцями надлопаткових залоз | С17M, С17P |
|
M18 |
Довжина лівої надлопаткової залози |
P18 | Відносна довжина лівої надлопаткової залози | С18M, С18P |
|
M19 |
Довжина правої надлопаткової залози |
P19 | Відносна довжина правої надлопаткової залози | С19M, С19P |
|
M20 |
Найбільша ширина лівої надлопаткової залози |
P20 | Відносна найбільша ширина лівої надлопаткової залози | С20M, С20P |
|
M21 |
Найбільша ширина правої надлопаткової залози |
P21 | Відносна найбільша ширина правої надлопаткової залози | С21M, С21P |
|
M22 |
Найменша відстань між надлопатковими залозами |
P22 | Відносна найменша відстань між надлопатковими залозами | С22M, С22P |
|
M23 |
Відстань від рострума до звуження між надлопатковими залозами |
P23 | Відносна відстань від рострума до звуження між надлопатковими залозами | С23M, С23P |
|
M24 |
Відстань від рострума до плечового суглоба |
P24 | Відносна відстань від рострума до плечового суглоба | С24M, С24P |
|
M25 |
Відстань від рострума до пахвової западини |
P25 | Відносна відстань від рострума до пахвової западини | С25M, С25P |
|
M26 |
Відстань від кута щелепи до пахвової западини |
P26 | Відносна відстань від кута щелепи до пахвової западини | С26M, С26P |
|
M27 |
Довжина передпліччя |
P27 | Відносна довжина передпліччя | С27M, С27P |
|
M28 |
Відстань від ліктьового суглоба до кінця пальців |
P28 | Відносна відстань від ліктьового суглоба до кінця пальців | С28M, С28P |
|
M29 |
Довжина зовнішнього горба зап'ястя |
P29 | Відносна довжина зовнішнього горба зап'ястя | С29M, С29P |
|
M30 |
Довжина внутрішнього горба зап'ястя |
P30 | Відносна довжина внутрішнього горба зап'ястя | С30M, С30P |
|
M31 |
Довжина тулуба між передніми і задніми ногами |
P31 | Відносна довжина тулуба між передніми і задніми ногами | С31M, С31P |
|
M32 |
Довжина стегна |
P32 | Відносна довжина стегна | С32M, С32P |
|
M33 |
Довжина гомілки |
P33 | Відносна довжина гомілки | С33M, С33P |
|
M34 |
Довжина найдовшого пальця від внутрішнього п'яткового горба |
P34 | Відносна довжина найдовшого пальця від внутрішнього п'яткового горба | С34M, С34P |
|
M35 |
Довжина внутрішнього пальця від внутрішнього п'яткового горба |
P35 | Відносна довжина внутрішнього пальця від внутрішнього п'яткового горба | С35M, С35P |
|
M36 |
Довжина внутрішнього п'яткового горба |
P36 | Відносна довжина внутрішнього п'яткового горба | С36M, С36P |
Таблиця 2.3.2. Фенетичні (альтернативні) та дискретні (включно з ранговими) ознаки, за якими були описані зелені ропухи (Bufotis viridis) у датафреймі Bufotis_viridis_database.RData
|
Код |
Ознака |
Стан ознаки |
Старий код |
|
F37 |
Дорсомедіальна смуга |
0 – відсутня; 1 – пряма, переривчаста; 2 – звивиста, безперервна; 3 – пряма, безперервна |
C37F |
|
F38 |
Яскравість плям на спині |
0 – відсутні; 1 – тьмяні; 2 – контрастні |
C38F |
|
F39 |
Відносна площа плям на спині |
0 – більше фону; 1 – фону і плям порівну; 2 – більше плям |
C39F |
|
F40 |
Розмір плям на спині |
0 – відсутні; 1 – менше ока; 2 – як око; 3 – більше ока |
C40F |
|
F41 |
З'єднаність плям на спині |
0 – плями ізольовані; 1 – з'єднані по кілька; 2 – єдиний візерунок |
C42F |
|
F42 |
Симетричність малюнка на спині |
0 – симетричний; 1 – відхилення від симетрії; 2 – асиметричний |
C43F |
|
F43 |
Біла облямівка плям на спині |
0 – відсутній; 1 – є |
C44F |
|
F44 |
Чорна облямівка плям спини |
0 – відсутній; 1 – є |
C45F |
|
F45 |
Межа залоз |
0 – розмита; 1 – різка |
C51F |
|
F46 |
Шипики на залозах |
0 – відсутні; 1 – є |
C52F |
|
F47 |
Розташування залоз |
0 – з проміжками; 1 – суцільно |
C53F |
|
F48 |
Наявність рядів спинних залоз |
0 – залози розташовані хаотично; 1 – залози розташовані рядами |
C54F |
|
F49 |
Розташування залоз на боці тулуба |
0 – відсутні; 1 – хаотичні; 2 – латеральний ряд у передній частині; 3 – повний латеральний ряд залоз |
C55F |
|
F50 |
Розташування залоз під латеральним рядом |
0 – відсутні; 1 – хаотичні; 2 – розташовані рядами |
C56F |
|
F51 |
Крапки на горлі |
0 – відсутні; 1 – є |
C57F |
|
F52 |
Дрібні плями на горлі |
0 – відсутні; 1 – рідкісні; 2 – часті |
C58F |
|
F53 |
Великі плями на горлі |
0 – відсутні; 1 – рідкісні; 2 – часті |
C59F |
|
F54 |
Пігментація тла горла |
0 – прозорий; 1 – білий; 2 – пігментований |
C60F |
|
F55 |
Точки на грудях |
0 – відсутні; 1 – є |
C61F |
|
F56 |
Дрібні плями на грудях |
0 – відсутні; 1 – рідкісні; 2 – часті |
C62F |
|
F57 |
Великі плями на грудях |
0 – відсутні; 1 – рідкісні; 2 – часті |
C63F |
|
F58 |
Пігментація тла грудей |
0 – прозорий; 1 – білий; 2 – пігментований |
C64F |
|
F59 |
Крапки на череві |
0 – відсутні; 1 – є |
C65F |
|
F60 |
Дрібні плями на череві |
0 – відсутні; 1 – рідкісні; 2 – часті |
C66F |
|
F61 |
Великі плями на череві |
0 – відсутні; 1 – рідкісні; 2 – часті |
C67F |
|
F62 |
Пігментація тла черева |
0 – прозорий; 1 – білий; 2 – пігментований |
C68F |
|
F63 |
Крапки на паху |
0 – відсутні; 1 – є |
C69F |
|
F64 |
Дрібні плями на паху |
0 – відсутні; 1 – рідкісні; 2 – часті |
C70F |
|
F65 |
Великі плями на паху |
0 – відсутні; 1 – рідкісні; 2 – часті |
C71F |
|
F66 |
Пігментація тла паху |
0 – прозорий; 1 – білий; 2 – пігментований |
C72F |
|
D67 |
Кількість плям-смуг на лівому передпліччі |
C75D | |
|
D68 |
Кількість плям-смуг на правому передпліччі |
C76D | |
|
D69 |
Кількість плям-смуг на лівій гомілці |
C77D | |
|
D70 |
Кількість плям-смуг на правій гомілці |
C78D | |
|
D71 |
Кількість 2-х суглобових горбків найдовшого пальця лівої задньої ноги |
C79D | |
|
D72 |
Кількість 2-х суглобових горбків найдовшого пальця правої задньої ноги |
C80D | |
|
D73 |
Кількість 3-х суглобових горбків найдовшого пальця лівої задньої ноги |
C81D | |
|
D74 |
Кількість 3-х суглобових горбків найдовшого пальця правої задньої ноги |
C82D | |
|
R75 |
Ранг довжини I пальця кисті |
Найдовшому пальцю відповідає ранг 1, іншим – у порядку зменшення довжини. Пальці однакової довжини мають однаковий ранг |
C83D |
|
R76 |
Ранг довжини II пальця кисті |
||
|
R77 |
Ранг довжини III пальця кисті |
||
|
R78 |
Ранг довжини IV пальця кисті |
||