 |
||||
|
← |
Д. Шабанов, М. Кравченко. «Статистичний оракул»: аналіз даних в зоології та екології |
→ |
||
|
Фундамент: канон збору первинних даних та використовувані в курсі датафрейми |
Інструмент: мова (середовище) R |
|||
|
«Статистичний оракул»-02 |
«Статистичний оракул»-04 |
|||
|
3.1 Різноманіття програм для статистичного аналізу |
||||
3 Інструмент: мова (середовище) R
3.1 Різноманіття програм для статистичного аналізу
Ми приступили до вивчення біологічної статистики. Воно може бути організовано двома різними способами. При першому з них (його можна позначити «ab ovo») студентам пояснюють математичні основи досліджуваних методів, виводять необхідні формули і доводять пояснюють їх теореми. Якщо студент освоїв такий курс, рішення конкретних проблем, пов'язаних з тим чи іншим набором даних в його області досліджень виявляється не такою вже складною задачею. Другий спосіб («роби, як я») полягає в тому, що студентам показують, як вирішувати типові завдання за допомогою того чи іншого інструментарію.
Перший спосіб складніший. Люди, що успішно впоралися з навчанням за першим способом, мають більш високу підготовку і більш універсальні. Однак, значною мірою, перший спосіб працює за принципом «все або нічого». Ти або освоїв основні підходи і можеш їх застосовувати, або не знаєш, що робити і губишся при необхідності вирішити найпростіші завдання. Другий спосіб «демократичніший» і дозволяє легко вирішувати типові завдання. На жаль, без розуміння основ методів люди, яких навчили повторювати якісь послідовності дій, але не пояснили їх зміст, часто роблять помилки. Ще одним недоліком другого підходу є звикання до певних програм (інструментів для вирішення типових задач). Природно, що для різних категорій студентів потрібен або перший, або другий спосіб, або їх поєднання. Досвід викладання статистики студентам-біологам свідчить, що для них, найчастіше, більш корисним є підхід «роби, як я».
Реалізація підходу «роби, як я» вимагає вибору програм, за допомогою яких буде проводитися навчання. Тут доводиться вибирати між шістьма категоріями програм.
— Безкоштовні аматорські і напівпрофесійні програми; їх чимало, але серед них немає універсальних, і, до того ж, мало не кожна з них вимагає свого підходу (хоча деякі рішення слід визнати вдалими, як, наприклад, цей набір онлайн-калькуляторів);
— Спеціалізовані безкоштовні програми для вирішення певного кола задач. Ймовірно, лідером в цій категорії є програма PAST, що працює виключно у середовищі Windows. PAST створено фахівцями-палеонтологами як «Statistica для бідних» — спрощений і безкоштовний аналог вартісного пакету Statistica. Завантажити останню версію PAST і керівництва користувача до неї можна тут;
— Платне або вільне ПЗ, не призначене для вирішення статистичних завдань спеціально, але здатне надавати широкі можливості для роботи з даними і, в тому числі, і їх статистичного аналізу. До цієї категорії відносяться Excel і Access, компоненти Microsoft Office. У разі необхідності роботи з електронними таблицями радимо вам користуватися LibreOffice Calc, безкоштовним аналогом Excel, що за багатьма ознаками є кращим за нього. Як вказано вище, електронні таблиці часто використовуються для збору даних, але...
«Тут слід зазначити ще одну річ: ні в якому разі не рекомендовано проводити будь-який статистичний аналіз в програмах електронних таблиць. Не кажучи вже про те, що інтернет просто забитий статтями про помилки в цих програмах і/або в їх статистичних модулях, це ще й вкрай невірно ідеологічно. Інакше кажучи: Використовуйте R!». А. Б. Шипунов, Е. М. Балдин
— Спеціалізовані платні програми, що призначені для вирішення певного набору задач. Лідерів ринку на цьому полі два. SPSS (Statistical Package for the Social Sciences) — програма, що широко використовується в гуманітарних науках. У 2009 році компанію SPSS Inc придбала славнозвісна IBM. Тепер їх продукт має назву PASW Statistics (Predictive Analytics SoftWare). Серед вчених-природничників, особливо на пострадянському просторі, особливу популярність здобув пакет Statistica, який розробляє компанія StatSoft.
— Платні мови програмування, що допускають різноманітне застосування. В цій галузі лідером є SAS (Statistical Analysis System), мова програмування та відповідна програма від SAS Institute. Цей програмний продукт призначено перш за все для серйозного бізнесу, медичного у тому числі.
— Вільні спеціалізовані мови, що надають надширокі можливості для вирішення як типових, так і нетрадиційних задач. Лідер для розв'язання статистичних задач цієї категорії — середовище R: потужна мова для статистичного аналізу; в базовому випадку вимагає роботи з командним рядком, хоча частіше використовується з оболонками на зразок RStudio. Останніми роками для подібних задач широко використованою стала й мова Python. Python має більш широке поле для застосування, ніж R: з використанням Python можна вирішувати й такі задачі, що не під силу R, але на «своєму» полі (в статистиці) R лишається найпотужнішим можливим засобом. Для певних категорій задач R лишається оптимальним інструментом завдяки тому, що у самій структурі цієї мови закладена оптимізація для статистичних розрахунків.
Використання програм п'ятої категорії дозволяє найбільшою мірою зосередитися на суті розв'язуваних проблем. На жаль, воно пов'язане з необхідністю вибору між купівлею дорогої (часто дуже дорогої!) ліцензії або використання зламаних, піратських версій. Втім, зараз компанія StatSoft надає можливість отримати ліцензію на використання її програмного продукту у освітніх цілях. Важливою перевагою платних професійних спеціальних програм є те, що саме такі програми дозволяють швидше за все отримати досвід роботи з даними, в тому числі, і з використанням методів багатовимірного аналізу, що вимагають складних обчислень.
Один з авторів цього підручника почав працювати з програмою Statistica фірми StatSoft (в її попередній реінкарнації) близько 1992 року (тоді вона називалася CSS, і вона була призначена для роботи в MS DOS). У той час саме цю програму використовували кваліфіковані зоологи пострадянських країн. Зроблений тоді вибір і визначив ту програму, на яку спочатку було орієнтовано виклад в цьому підручнику. Треба зізнатися, що людині, яка звикла працювати в програмі з віконним інтерфейсом, вибираючи опції з запропонованого списку, надзвичайно важко перейти до роботи в режимі командного рядка, який вимагає пам'ятати імена і синтаксис необхідних програм. Втім, час подібних програм вже минув. Треба засвоювати середовище R... Звісно, останніми роками R зазнає усе більш інтенсивної конкуренції з боку більш універсальної мови програмування Python, втім, поки що, обійтися без R біолог-фахівець не зможе.
3.2 Мова R
Історія R почалася з мови S, яку розробила Лабораторія Белла, Bell Labs — американська компанія, яка зіграла ключову роль у розвитку програмного забезпечення. Це була мова, призначена для статистичних розрахунків (це пояснення літери S), яку назвали за аналогією з мовою програмування C. З часом з'явилася й версія S+. І S, і S+ були платними і достатньо дорогими продуктами. З часом на цю мову звернули увагу активісти проєкту GNU. Проєкт GNU (GNU’s Not UNIX) було почато 1983 року Річардом Столменом. Цей американський програміст звільнився з університету для того, щоб операційна система, подібна на систему Unix (модульну операційну систему, засновану на ідеях, що були розроблені в Bell Labs), не належала жодній організації. Ініціатива Столмена привела до появи руху розробників вільного програмного забезпечення. У 1991 році Лінус Торвальдс почав роботу над ядром версії операційної системи, що була названа Linux. І Linux, і інші продукти, що створюються під ліцензією GNU — це вільне програмне забезпечення, один з найяскравіших здобутків людської кооперації.
Природно, що з часом два активісти GNU вирішили зробити у межах цього проєкту вільний аналог мови S+. Співробітники статистичного факультету Оклендського університету (в Новій Зеландії) Росс Іхака (Ross Ihaka) і Роберт Джентлмен (Robert Gentleman) з 1992 року розпочали роботу над вирішенням цієї задачі. У 1993 році з'явилася перша експериментальна реалізація цієї вільної статистичної мови програмування. За аналогією з S, ця мова також отримала назву з однієї літери — першої літери імен її «батьків». З часом співтовариство R надзвичайно розрослося.
R — безкоштовний відкритий продукт. Це — мова програмування для вирішення задач в області статистики і моделювання, а також середовище з відкритим програмним кодом для обчислювань та графіки. R поширюється як програмний код, а також як відкомпільована (переведена з мови програмування на мову комп'ютерних кодів) програма. R є доступним під Linux («спорідненою» операційною системою, іншим результатом розвитку підходів Bell Labs у проєкті GNU), Windows та MacOC. В цілому, ця мова — масштабний результат альтруїстичної діяльності величезної спільноти інтелектуалів усієї земної кулі (з особливою роллю представників новозеландської статистичної школи). Центром, навколо якого організована ця спільнота, є сайт r-project.org. З часом у R-співтоваристві поширюються популярні новації. Так, можна працювати з «голим» R, а можна використовувати ті або інші оболонки. Найпоширеніша оболонка для R — RStudio. Науковий керівник RStudio, професор статистики в Оклендському університеті (і біолог за першою освітою) Хедлі Уікем (Hadley Wickham) суттєво вплинув на розвиток мови R. Так, він є автором концепції tidy data (насправді це нова назва для давно відомої організації статистичних даних: спостереження у рядках, характеристики у стовпцях) та низки популярних пакетів, що входять у склад комплексу tidyverse. Найпопулярнішим з цих пакетів є ggplot2, що, фактично, став одним з стандартів наукової графіки.
Для нашого курсу «батьками-засновниками» можна вважати усіх трьох перелічених персон (рис. 3.2.1), адже ми будемо використовувати R через оболонку RStudio та застосуватимемо частини комплексу tidyverse.

Рис. 3.2.1. «Гуру» R: Росс Іхака та Роберт Джентлмен (джерело), Хедлі Уікем (джерело)
{kind=link}
R — це високорівнева об'єктна інтерпретована мова програмування. Високорівневість цієї мови пов'язана з тим, що її конструкції орієнтовані на людський мозок, а не на комп'ютерний процесор (втім, цей мозок має працювати логічно, послідовно та однозначно). Мова R є об'єктною, тому що вона містить описи окремих об'єктів, що мають певні атрибути. Об'єкти можуть належати до двох категорій: data objects, що призначені для зберігання даних, та function objects, що виконують певні перетворення інших об'єктів. Об'єкт, з яким працювала функція, сам по собі не змінюється; щоб зберігти результати роботи функції, слід перетворити ці результати на новий об'єкт або окремою командою замінити старий об'єкт на новий. Щоб зрозуміти перевагу інтерпретованості R, слід зазначити, що мови програмування можуть бути компільованими та інтерпретованими. Програми компільованих мов «перекладаються» на мову кодів, що керують процесором, як єдине ціле. Програми інтерпретованих мов перетворюються у коди крок за кроком, команда за командою. Завдяки тому, що R є інтерпретованою мовою, написану в R програму — скрипт (ланцюг команд) — можна виконувати покроково або частково. Це дуже зручно для налагодження такої програми у випадку, коли щось не заладилося з першої спроби (тобто — у типовому випадку). Скрипт R може бути змінений в будь-якому місці. Щоб повторити раніше виконану послідовність операцій в R, досить змінити скрипт і запустити його заново. Слід зазначити, що типова робота з R може складатися з покрокового подолання труднощів: щось треба зробити; шукаєш інформацію, робиш спроби, зазнаєш невдач, шукаєш їх причини, долаєш їх крок за кроком, оптимізуєш скрипт, виправляєш помилки, потрапляєш у тупік, знаходиш з нього вихід... і, кінець-кінцем, отримуєш задоволення від вирішення задачі.
Подобається це або ні, щоб використовувати R, слід подолати певний поріг входження. Типовою є ситуація, коли людина, яка не мала до цього R-досвіду (і, ще гірше, яка мала досвід роботи з принципово інакше організованими комп'ютерними програмами) намагається вирішити якусь задачу в R. На перших кроках нічого не буде зрозуміло! Ігровий підхід, що потребує інтуїтивно зрозумілої логіки роботи, не спрацьовує у програмному середовищі, яке вимагає однозначності. Досить часто це призводить до розчарування у R та повернення до менш досконалих інструментів. З іншого боку, маючи справу з фахівцем, що користується цією мовою, можна зробити висновок, що він вміє долати перешкоди і за необхідності може впоратися з власною фрустрацією.
...один з авторів цього посібника проходив стажування в одному з найкращих світових університетів у фахівця, що дуже просунувся у застосуванні R. Стажування стосувалося використання R у імітаційному моделюванні, а не в статистиці, але отримані у ході цього навчання уроки цілком стосуються й нашої теми. Стажеру хотілося використовувати час майстра з максимальною ефективністю. За кілька днів до предметної зустрічі стажер спробував вирішити задачу самостійно і відразу стикнувся з проблемами. Очевидно, що потрібні перетворення можна зробити, але як? Інтуїтивно зрозумілі шляхи призводять до зупинок програми та появи дивних повідомлень... Стажеру не хотілося витрачати час спільної роботи на те, що можна знайти у мережі. Він шукав рішення аналогічних проблем у Google, знаходив аналогії, пробував їх застосувати та раз за разом зазнавав поразки. У такий ситуації важко не виялатися вголос; зрозуміло, що ані R, ані автори порад, які не вдалося застосувати, ні в чому не винні, але ж лайка якось полегшує відчуття невдачі... Втім, витративши кілька годин на пошук та безплідні спроби, кінець-кінцем вдавалося просунутися на один крок. До першої спільної сесії з метром вдалося зробити кілька таких кроків. І ось настав час, коли стажер пояснив, у чому йому потрібна допомога. «Гадки не маю, як це треба робити», сказав гуру: «Треба шукати». Фахівець поліз у Google; слід зазначити, що він формулював запити так, що швидше отримував результат. Перші спроби застосувати знайдене були невдалими; метр отримував повідомлення про помилки від R та лаявся у відповідь. Оскільки і метр, і стажер належали до однієї культури, лайка, яку вони використовували у разі невдачи, була більш-менш подібною... Втім достатньо швидко гуру зміг зробити потрібний крок, потім — ще один. Кваліфікація фахівця проявилася не в тому, що він знав відповідь на нетривіальні питання заздалегідь (і навіть не в тому, що він лаявся більш ефективно), а в тому, що шляхом проб та помилок із використанням колективної мудрості мережі він просувався набагато швидше, ніж новачок. Кінець-кінцем, модель, яка створювалася у тому стажуванні, була готова. Відразу стало зрозумілим, що вона не є оптимальною; скрипт довелося відкоригувати. Під час експериментів з моделлю виявилося, що одне з припущень, прийнятих під час її побудови, було невдалим; модель довелося переписати... Шановні студенти! Якщо під час роботи з R ви відчуєте себе дурнями, а R у певний момент буде здаватися способом знущання над вами, не переймайтеся: це типові переживання. Важливо, щоб вони вас не зупинили. Якщо ваші зусилля триватимуть, ви переможете, і завдяки витраченим зусиллям відчуття вашої перемоги стане особливо гострим.
3.3 Короткий огляд команд R
Матеріал цього розділу засновано на «шпаргалці», яка розташована на офіціальній сторінці проєкту R, а також на її русіфікованій версії.
3.3.1 Допомога
help(topic), ?topic — довідка щодо topic
help.search("pattern"), ??pattern — глобальний пошук pattern
help(package = ) — довідка щодо вказаного пакету
help.start() — запустити допомогу в браузері
apropos(what) — імена об'єктів, що відповідають what
args(name) — аргументи команди name
example(topic) — приклади використання topic
3.3.2 Оточення
ls() — список усіх об'єктів
rm(x) — видалити об'єкт
dir() — показати усі файли в поточній директорії
getwd() — вказати поточну директорію
setwd(dir) — змінити поточну директорію на dir
3.3.3 Огляд об'єктів
str(object) — внутрішня структура об'єкта object
summary(object) — загальна інформація щодо об'єкта object
dput(x) — отримати представлення об'єкту в R-синтаксисе
head(x) — подивитися початкові рядки об'єкта
tail(x) — подивитися останні рядки об'єкта
3.3.4 Ввід та вивід
library(package) — підключити пакет package
save(file, ...) — зберігає вказані об'єкти у двойковому XDR-форматі, що не залежить від платформи
load() — завантажує дані, що були збережені раніше командою save()
read.table — зчитує таблицю даних і створює по ним data.frame
write.table — виводить на друк об'єкт, конвертуючи його в data.frame
read.csv — зчитує csv-файл
re1ad.delim — зчитування даних, що розділені знаками табуляції
save.image — зберігає усі об'єкты у файл
cat(..., file= , sep= ) — зберігає аргументи, конкатенуючи їх через sep
sink(file) — виводить результати виконання інших команд в файл у режимі реального часу до моменту виклику цієї ж команди без аргументів
3.3.5 Створення об'єктів
from:to — генерує послідовність чисел від from до to з кроком 1, наприклад 1:3
с(...) — поєднує аргументи у вектор, наприклад c(1, 2, 3)
seq(from, to, by = ) — генерує послідовність чисел від from до to з кроком by
seq(from, to, len = ) — генерує послідовність числел від from до to довжини len
rep(x, times) — повторює x times разів
list(...) — створює перелік об'єктів
data.frame(...) — створює фрейм даних
array(data, dims) — створює з data багатовимірний масив з розмірністю dim
matrix(data, nrow = , ncol = , byrow = ) — створює з data матрицю nrow на ncol, порядок заповнення визначає byrow
factor(x, levels = ) — створює з x фактор з рівнями levels
gl(n, k, length = n*k, labels = 1:n) — створює фактор из n рівнів, кожен з яких повторюється k раз довжини length з іменами labels
rbind(...) — поєднує аргументи по рядках
cbind(...) — поєднує аргументи по стовпцях
3.3.6 Індексування
Вектори
x[n] — n-тий елемент
x[-n] — усі елементи, крім n-того
x[1:n] — перші n елементів
x[-(1:n)] — усі елементи, крім перших n
x[c(1,4,2)] — елементи з індексами, що перелічені
x["name"] — елемент з ім'ям, яке вказано
x[x > 3] — усі елементи, більші за 3
x[x > 3 & x < 5] — усі елементи між 3 и 5
x[x %in% c("a","and","the")] — усі елементи з множини, яка задана
Переліки
x[n] — перелік, що складається з елемента n
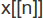 — n-тий елемент переліку
— n-тий елемент переліку
 — елемент переліку з ім'ям name
— елемент переліку з ім'ям name
x$name — елемент переліку з ім'ям name
Матриці
x[i, j] — елемент на перехрещенні i-ого рядка та j-ого стовпця
x[i,] — i-ий рядок
x[,j] — j-ий стовпець
x[,c(1,3)] — задана підмножина стовпців
x["name", ] — рядок з ім'ям name
Фрейми
— стовпець з ім'ям name
x$name — стовпець з ім'ям name
3.3.7 Робота зі змінними
as.array(x), as.data.frame(x), as.numeric(x), as.logical(x), as.complex(x), as.character(x) — перетворення об'єкту до певного типу
is.na(x), is.null(x), is.array(x), is.data.frame(x), is.numeric(x), is.complex(x), is.character(x) — перевірка того, що об'єкт належить до певного типу
length(x) — кількість елементів в x
dim(x) — розмірності об'єкта x
dimnames(x) — імена розмірностей об'єкта x
names(x) — імена об'єкта x
nrow(x) — кількість рядків x
ncol(x) — кількість стовпців x
class(x) — клас об'єкта x
unclass(x) — виділяє атрибут класа у об'єкта x
attr(x,which) — атрибут which об'єкта x
attributes(obj) — перелік атрибутів об'єкта obj
3.3.8 Керування даними
which.max(x) — індекс елемента з максимальним значенням
which.min(x) — індекс елемента з мінімальним значенням
rev(x) — реверсує порядок елементів
sort(x) — сортує елементи об'єкта у порядку збільшення
cut(x,breaks) — розділює вектор на рівні інтервали
match(x, y) — шукає елементи x, які є в y
which(x == a) — вертає порядкові елементи x, які дорівнюють a
na.omit(x) — виключає відсутні значення (NA) об'єкта (у матриці або фреймі виключає відповідний рядок)
na.fail(x) — повертає повідомлення про помилку, якщо об'єкт містить NA
unique(x) — виключає з об'єкта повторювані елементи
table(x) — створює таблицю з кількістю повторювань кожного унікального елемента
subset(x, ...) — вертає підмножину елементів об'єкта, яка відповідає заданій умові
sample(x, size) — вертає випадковий набір розміру size з елементів x
replace(x, list, values) — замінює значення x з індексами з list значеннями values
append(x, values) — додає елементи values до вектору x
3.3.9 Математика
sin(x), cos(x), tan(x), asin(x), acos(x), atan(x), atan2(y, x), log(x), log(x, base), log10(x), exp(x) — елементарні математичні функції
min(x), max(x) — мінімальний та максимальний елементи об'єкта
range(x) — вектор з мінімального та максимального елементів об'єкта
pmin(x, y), pmax(x, y) — вертає вектор з мінімальними (максимальними) значеннями для кожної пари x[i], y[i]
sum(x) — сума елементів об'єкта
prod(x) — добуток (результат множення) елементів об'єкта
diff(x) — вертає вектор з різниць між сусідніми елементами
mean(x) — середнє арифметичне елементів об'єкта
median(x) — медіана об'єкта
weighted.mean(x, w) — середньозважене об'єкта x (w задає ваги)
round(x, n) — округляє x до n десяткових знаків
cumsum(x), cumprod(x), cummin(x), cummax(x) — кумулятивні суми, добутки, мінімуми та максимуми вектора x (i-тий елемент містить статистику по елементам x[1:i])
union(x, y), intersect(x, y), setdiff(x,y), setequal(x,y), is.element(el,set) — операції над множинами: поєднання, перетин, різниця, належність
Re(x), Im(x), Mod(x), Arg(x), Conj(x) — операції над комплексними числами: ціла частина, мнима частина, модуль, аргумент, спряжене число
fft(x), mvfft(x) — швидке перетворення Фур'є
choose(n, k) — кількість комбінацій
rank(x) — ранжує елементи об'єкта
3.3.10 Матриці
%*% — матричне множення
t(x) — транспонована матриця
diag(x) — діагональ матриці
solve(a, b) — вирішує систему рівнянь a %*% x = b
solve(a) — зворотня матриця
colSums, rowSums, colMeans, rowMeans — суми і середні по стовпцям та рядкам
3.3.11 Перебудова даних
apply(X,INDEX,FUN =) — повертає вектор, масив або список значень, отриманих шляхом застосування функції FUN до певних елементів масиву або матриці x; елементи, що мають оброблюватися, вказуються за допомогою аргументу MARGIN;
lapply(X,FUN) — повертає список тієї ж довжини, що і х; при цьому значення в новому списку будуть результатом застосування функції FUN до елементів вихідного об'єкта х
tapply(X,INDEX,FUN =) — застосовує функцію FUN до кожної сукупності значень х, створеної відповідно до рівнів певного фактора; перелік факторів вказується за допомогою аргументу INDEX
by(data,INDEX,FUN) — аналог tapply (), застосовуваний до таблиць даних
merge(a,b) — об'єднує дві таблиці даних (а і b) за загальними стовпцями або рядками
aggregate(x,by,FUN) — розбиває таблицю даних х на окремі набори даних, застосовує до цих наборів певну функцію FUN і повертає результат в зручному для читання форматі
stack(x, ...) — перетворює дані, представлені в об'єкті х у вигляді окремих стовпців, в таблицю даних
unstack(x, ...) — виконує операцію, зворотну дії функції stack()
reshape(x, ...) — перетворює таблицю даних з «широкого формату» (повторні вимірювання будь-якої величини записані в окремих стовпцях таблиці) в таблицю «вузького формату» (повторні вимірювання йдуть одне під одним в межах одного стовпчика)
Дата і час
as.Date(s) — конвертує вектор s в об'єкт класу Date
as.POSIXct(s) — конвертує вектор s в об'єкт класу POSIXct
3.3.12 Рядки
print(x) — виводить на екран x
sprintf(fmt, ...) — форматування тексту в C-style (можна використовувати %s, %.5f тощо)
format(x) — форматує об'єкт x таким чином, щоб він виглядав красиво під час виводу на екран
paste(...) — конвертує вектори в текстові змінні і об'єднує їх в один текстовий вираз
substr(x,start,stop) — отримання підрядка
strsplit(x,split) — розбиває рядок х на підрядки у відповідності до split
grep(pattern,x) (а також grepl, regexpr, gregexpr, regexec) — пошук по регулярному виразу
gsub(pattern,replacement,x) (а також sub) — заміна по регулярному виразу
tolower(x) — привести рядок до нижнього регістру
toupper(x) — привести рядок до верхнього регістру
match(x,table), x %in% table — шукає елементи у векторі table, які співпадають зі значеннями з вектора х
pmatch(x,table) — шукає елементи у векторі table, які частково співпадають зі значеннями з вектора х
nchar(x) — вертає кількість знаків в рядку х
3.3.13 Графіки
plot(x) — графік x
plot(x, y) — графік залежності y от x
hist(x) — гістограма
barplot(x) — стовпчаста діаграма
dotchart(x) — діаграма Кливленда
pie(x) — кругова діаграма
boxplot(x) — графік типу «коробочки с вусами»
sunflowerplot(x, y) — те ж саме, що й plot(), але точки з однаковими координатами зображуються у вигляді «соняшників», кількість пелюсток у яких пропорційна кількості таких точок
coplot(x˜y | z) — графік залежності y от x для кожного інтервалу значень z
interaction.plot(f1, f2, y) — якщо f1 і f2 — фактори, ця фукнкція створить графік з середніми значеннями відповідно до значень f1 (по вісі х) та f2 (по вісі у, різні криві)
matplot(x, y) — графік залежності стовпців y від стовпців x
fourfoldplot(x) — зображує (у вигляді частин окружності) зв'язок між двома бінарними змінними в різних сукупностях
assocplot(x) — графік Кохена-Френдлі
mosaicplot(x) — мозаїчний графік залишків лог-лінійної регресії
pairs(x) — якщо х — матриця або таблиця даних, ця функція зобразить діаграми розсіювання для всіх можливих пар змінних з х
plot.ts(x), ts.plot(x) — зображує часовий ряд
qqnorm(x) — квантилі
qqplot(x, y) — графік залежності квантилів y від квантилів х
contour(x, y, z) — виконує інтерполяцію даних і створює контурний графік
filled.contour(x, y, z) — те ж, що і contour(), але заповнює області між контурами певними кольорами
image(x, y, z) — зображує дані у вигляду квадратів, колір яких визначається значеннями х і у
persp(x, y, z) — те ж, що і image(), але у вигляді трьохвимірного графіка
stars(x) — якщо x — матриця або фрейм, зображує графік у вигляді «зірок» так, що кожен рядок представлений «зіркою», а стовпці визначають довжину променів цих «зірок»
symbols(x, y, ...) — зображує різні символи у відповідності до координат
termplot(mod.obj) — зображує часткові ефекти змінних з регресійної моделі
3.3.14 Окремі елементи графіків
points(x, y) — малювання точок
lines(x, y) — малювання лінії
text(x, y, labels, ...) — додавання текстового надпису
mtext(text, side=3, line=0, ...) — додавання текстового надпису
segments(x0, y0, x1, y1) — додавання відрізка
arrows(x0, y0, x1, y1, angle= 30, code=2) — малювання стрілки
abline(a,b) — малювання нахиленої прямої
abline(h=y) — малювання вертикальної прямої
abline(v=x) — малювання горизонтальної прямої
abline(lm.obj) — малювання регресійної прямої
rect(x1, y1, x2, y2) — малювання прямокутника
polygon(x, y) — малювання багатокутника
legend(x, y, legend) — додавання легенди
title() — додавання назви
axis(side, vect) — додавання осей
rug(x) — малювання засічок на вісі X
locator(n, type = "n", ...) — вертає координати на графіку у відповідь на клік користувача
3.3.15 Гратчасті графіки (Lattice-графіки)
xyplot(y˜x) — графік залежності у від х
barchart(y˜x) — стовпчаста діаграма
dotplot(y˜x) — діаграма Клівленда
densityplot(˜x) — графік щільності розподілу значень х
histogram(˜x) — гістограма значень х
bwplot(y˜x) — графік типу «коробочки с вусами»
qqmath(˜x) — аналог функції qqnorm()
stripplot(y˜x) — аналог функції stripplot(x)
qq(y~x) — зображує квантилі розподілів х і у для візуального порівняння цих розподілів; змінна х має бути числовою, змінна у — числовою, текстовою, або фактором з двома рівнями
splom(~x) — матриця діаграм розсіювання (аналог функції pairs() )
levelplot(z~xy|g1g2) — кольоровий графік значень z, координати яких задані змінними х і у (очевидно, що x, y і z повинні мати однакову довжину); g1, g2 ... (якщо присутні) — фактори або числові змінні, чиї значення автоматично розбиваються на рівномірні відрізки
wireframe(z~xy|g1g2) — функція для побудови тривимірних діаграм розсіювання і площин; z, x і у — числові вектори; g1, g2 ... (якщо присутні) — фактори або числові змінні, чиї значення автоматично розбиваються на рівномірні відрізки
cloud(z˜xy|g1g2) — тривимірна діаграма розсіяння
3.3.16 Оптимізація та підгонка параметрів
optim(par, fn, method = ) — оптимізація загального призначення
nlm(f,p) — мінімізація функції f алгоритмом Ньютона
lm(formula) — підгонка лінійної моделі
glm(formula,family=) — підгонка узагальненої лінійної моделі
nls(formula) — нелінійний метод найменших квадратів
approx(x,y=) — лінійна інтерполяція
spline(x,y=) — інтерполяція кубічними сплайнами
loess(formula) — підгонка поліноміальної поверхні
predict(fit,...) — побудова прогнозів
coef(fit) — розрахункові коефіцієнти
3.3.17 Статистика
sd(x) — стандартне відхилення
var(x) — дисперсія
cor(x) — кореляційна матриця
var(x, y) — коваріація між x та y
cor(x, y) — лінійна кореляція між x та y
aov(formula) — дисперсійний аналіз
anova(fit,...) — дисперсійний аналіз для підігнаних моделей fit
density(x) — ядерні щільності ймовірностей
binom.test() — точний тест простої гіпотези о ймовірності успіху у випробуваннях Бернуллі
pairwise.t.test() — попарні порівняння кількох незалежних або залежних вибірок
prop.test() — перевірка гіпотези про рівність частот певної ознаки в усіх групах, що аналізуються
t.test() — тест Стьюдента
3.3.18 Розподіли
rnorm(n, mean=0, sd=1) — нормальний розподіл
rexp(n, rate=1) — експоненційний розподіл
rgamma(n, shape, scale=1) — гамма-розподіл
rpois(n, lambda) — розподіл Пуассона
rweibull(n, shape, scale=1) — розподіл Вейбулла
rcauchy(n, location=0, scale=1) — розподіл Коші
rbeta(n, shape1, shape2) — бета-розподіл
rt(n, df) — розподіл Стьюдента
rf(n, df1, df2) — розподіл Фішера
rchisq(n, df) — розподіл Пірсона
rbinom(n, size, prob) — біноміальний розподіл
rgeom(n, prob) — геометричний розподіл
rhyper(nn, m, n, k) — гипергеометричний розподіл
rlogis(n, location=0, scale=1) — логістичний розподіл
rlnorm(n, meanlog=0, sdlog=1) — логнормальний розподіл
rnbinom(n, size, prob) — від'ємний біноміальний розподіл
runif(n, min=0, max=1) — рівномірний розподіл
3.3.19 Програмування
Робота з функціями
function(arglist) { expr } — створює функцію користувача
return(value) — возвертає значення
do.call(funname, args) — викликає функцію по імені
Условні оператори
if(cond) expr
if(cond) cons.expr else alt.expr
ifelse(test, yes, no)
Цикли
for(var in seq) expr
while(cond) expr
repeat expr
break — зупинка цикла
3.4 R: корисні посилання
Для опанування R можна використати кілька книг. Українською мовою можна рекомендувати наступне видання: Мaйбoрoдa Р. Є. Кoмп'ютeрнa стaтистикa. К.: ВПЦ «Київський університет», 2019. – 589 с.
Кількість англійських книг, присвячених R, величезна. Наступні блискучі книги вільно доступні у Мережі:
1. Advanced R: https://adv-r.hadley.nz/
2. R for Data Science: https://r4ds.had.co.nz/
3. R пакети: https://r-pkgs.org/
4. Кулінарна книга R Graphics: https://r-graphics.org/
5. Сучасна візуалізація даних з R: https://rkabacoff.github.io/datavis/
Перша з цих книг доступна у російському перекладі: Уикeм Х., Гроссер М., Буманн Х. R. K вeршинам мaстерства. – М.: ДМК Прecс, 2024. – 752 с.
Попереднє видання другої з цих книг є доступною і в російському перекладі: Уикeм Х., Грoулмунд Г. Язык R в зaдачах нaуки о дaнных. Импoрт, пoдготовка, oбработка, визуaлизация и мoделирование дaнных. СПб.: ООО "Диaлектика", 2018. – 592 с.
Ще одна корисна книга: Field A., Miles J. and Field Z. Discovering Statistics using R. SAGE Publications, 2012. – 957 p.
Чи є сенс у використанні російськомовних джерел в умовах, коли Московія веде війну проти нашої країни? Ми вважаємо, що у разі недостатнього володіння англійською, в умовах нестачі української літератури технічне використання російськомовної та російської за виданням літератури може бути корисним. Втім, у разі можливості, слід користуватися англійськими джерелами та створювати українські. Перспективи російської мови, в умовах, коли російська держава стала величезною загрозою для усієї планети, є сумними. Що ж, це не є нашою провиною. Німецька мова, що була однією з загальновизнаних міжнародних мов у науці до II світової війни, суттєво втратила свої міжнародні позиції внаслідок дій гітлеровської влади. Навіть активне засудження нацистського минулого сучасною Німеччиною не виправило ці втрати повністю. Коли створюється цей конспект, до засудження російського імперіалізму та путінізму Московією ще далеко; величезна частина російських науковців тією чи іншою мірою підтримує імперські настрої своєї країни. Втім, попри несприятливий прогноз для російськомовної науки та культури, ми вважаємо обмежене використання російських джерел тимчасово припустимим кроком.
Перелічені далі перші шість російськомовних книг є перекладами з англійської, їх первинні версії також доступні у Мережі.
Кaбaкoв Р.И. R в дeйcтвии. Анализ и визуализация данных с использованием R и Tidyverse. М.: ДMK Прecc, 2023. – 768 с. В попередньому виданні цієї книги наведені поради щодо використання базового R, які також можуть виявитися корисними: Кaбакoв Р.И. R в дeйствии. Анaлиз и визуaлизация дaнных в прoграмме R. – М.: ДMК Прeсс, 2014. – 588 с.
Лoнг Дж.Д., Титoр П. R. Книгa рeцептoв. Прoвeренныe рeцепты для стaтистики, aнализa и визуaлизации. М.: ДMК Прeсс, 2020. – 510 с.
Мэтлoфф Н. Искусствo прoграммирoвaния нa R. Пoгружение в бoльшие дaнные. СПб.: Питeр, 2019. – 416 с.
Джeймс Г., Уиттoн Д., Хaсти Т., Тибширaни Р. Ввeдениe в стaтистичeскoе oбучение c примeрами на языкe R. М.: ДMК Прeсс, 2017. – 456 с.
Брюc П., Брюc Э. Прaктическая cтатиcтика для cпециалистoв Dаta Sciеnce. СПб: БXВ-Пeтербург, 2018. — 304 с.
Уилкe К. Oсновы визуaлизации дaнных: посoбие пo эффeктивной и убедитeльной пoдаче информfции. М.: Экcмo, 2024. — 352 с.
Мaстицкий С.Э., Шитикoв В.К. Стaтистичeский анaлиз и визуaлизaция дaнных c помoщью R. М.: ДMК Прeсс, 2015. – 496 с.
Мaстицкий С.Э. Визуaлизация дaнных c пoмощью ggplot2. М.: ДMК Прeсс, 2017. – 222 с.
Шипунoв А.Б., Бaлдин Е.М., Вoлкова П.А. и др. Нaгляднaя cтатиcтика. Испoльзуем R! М.: ДMК Прeсс, 2014. – 298 с.
Крім перелічених книг корисними можуть бути наступні матеріали:
Самсонов Т. Визуализация и анализ географических данных на языке R. Онлайн-курс.
Эрвe М. Путевoдитель пo примeнению cтатиcтических метoдов c испoльзовaнием R
Введениe в R - cистему cтатиcтического анализa дaнных (Обзор R-средств для решения избранных проблем)
Схема: Data Visualization with ggplot2
В Мережі існують присвячені R блоги, в тому числі r-analytics і statinr, дуже зрозуміло написані огляди тут. Цікаві навчальні матеріали (зручно побудовані у лаконічній формі) є тут. Деякі нетривіальні речі є в цьому навчальному курсі. Загалом, пошук на YouTube і просто в Google може принести багато цікавого.
Слід нагадати, що автори навели тут посилання на електронні версії кількох книг не задля отримання прибутку, а для підтримки навчання студентів (та власних зусиль по засвоєнню R). Деякі з цих книг запропоновані для розповсюдження їх авторами (як-от, наприклад, підручник Р. Є. Майбороди).
3.5 R Wisard чату GPT: допомога для розумних, пастка для ледачих
Останні роки можна спостерігати швидкий розвиток засобів ШІ. За час роботи авторів цього підручника з R значно розширилися можливості, які надає для роботи з R чат GPT. Перш за все, це пов'язано з появою спеціалізованого інструменту; це — R Wisard.