|
|
||||
|
БІОСИСТЕМИ. БІОСФЕРА
ЕКОСИСТЕМИ. ПОПУЛЯЦІЇ
ОРГАНІЗМИ У ДОВКІЛЛІ
ЛЮДСТВО ТА ЙОГО ДОЛЯ
|
||||
|
Додаток VII. Напівфабрикати для створення R-моделей |
|
|||

Додаток VII. Напівфабрикати для створення R-моделей
Задум цієї сторінки простий: зібрати на ній фрагменти R-скриптів, які можуть бути корисними при створенні нових моделей. Як назвати ці фрагменти? Приклади? Зразки? Шаблони? «Заготовини»? Рецепти? Нехай буде «напівфабрикати», semifinished. Наповнення цієї сторінки триває; багато чого в цій роботі лишається незрозумілим (наприклад, непросто вирішити, у якому порядку розташовувати ці напівфабрикати). Втім, будемо сподіватися, що результат цієї роботи буде корисним для студентів, що засвоюють даний курс. На цей час наявні наступні напівфабрикати:
Початок роботи
Типова структура моделі
Початкові команди скрипту
Читання та запис файлу з даними
Створення та перетворення об'єктів
Створення пустого вектору певної довжини
Створення пустої матриці з іменованими рядками та стовпцями
Сортування рядків в матриці за значеннями певного стовпця
Отримання параметрів певних категорій особин з таблиці з кодами; користувацька функція
Створення групи випадкових чисел
Імітування випадкових подій
Ймовірнісне округлення
Формування випадкової вибірки за допомогою функції sample ()
Моделювання добору за допомогою функції sample () та “вектора долі”
Власна функція конкурентного скорочення чисельності (імітація на рівні груп)
Скорочення чисельності популяції внаслідок добору (імітація на рівні особин)
Неконкурентне імітаційне скорочення чисельності (імітація на рівні особин)
Конкурентне скорочення популяції з різних форм особин
Керування розрахунками
Перемикач у разі множинного вибору: switch()
Перебір значень початкових параметрів
Виведення у консоль звітів про прогрес у розрахунках
Елементи статистики
Розрахунок кореляції між двома ознаками
Візуалізація результатів
Побудова простої діаграми розсіювання (scatterplot)
Діаграма розсіювання з лінією регресії
Побудова лінійного графіку для трьох змінних (line chart)
“Теплова карта” кореляції між багатьма ознаками
Тривимірна візуалізація результатів перебору параметрів
Приклади моделей
Конкуренція двох клонів в популяції, що зростає логістично
Конкуренція двох видів згідно моделі Лотки-Вольтерра (у логістичному вигляді) з лагом реакції
Порівняння (і “перегони”) арифметичного та геометричного зростання
Початок роботи
Типова структура моделі
У більшості моделей нема сенсу використовувати усі перелічені елементи структури, але певна частина з них буде корисною. Ця структура не є догмою, але її притримання (хоча б приблизне) і використання в тексті скрипта запропонованих підрозділів поліпшить розуміння моделей тими користувачами, що її засвоїли.
# I_N_I_T_I_A_L_I_Z_A_T_I_O_N — І_Н_І_Ц_І_А_Л_І_З_А_Ц_І_Я, ПЕРВИННІ КОМАНДИ
# HEADLINE — НАЗВА:
# EXPLANATIONS — ПОЯСНЕННЯ:
# INITIAL SCRIPT COMMANDS — ПОЧАТКОВІ КОМАНДИ СКРИПТУ:
# E_N_T_R_A_N_C_E — В_Х_І_Д_Н_І___К_О_М_А_Н_Д_И
# MAIN PARAMETERS — ГОЛОВНІ ПАРАМЕТРИ:
# EXPERIMENTAL CONDITIONS — УМОВИ ЕКСПЕРИМЕНТУ:
# CHANGEABLE PARAMETERS COMBINATIONS IN TYPE III MODELS — ЗМІННІ КОМБІНАЦІЇ ПАРАМЕТРІВ У МОДЕЛЯХ III ТИПУ:
# R_U_L_E_S_S_E_T_U_P — Н_А_Л_А_Ш_Т_У_В_А_Н_Н_Я___П_Р_А_В_И_Л
# CREATING A SYMBOLS / PARAMETERS TABLE — СТВОРЕННЯ ТАБЛИЦІ СИМВОЛИ / ПАРАМЕТРИ:
# ADJUSTING THE SYMBOLS / PARAMETERS TABLE — НАЛАШТУВАННЯ ТАБЛИЦІ СИМВОЛИ / ПАРАМЕТРИ:
# CREATING A PARENTS / OFFSPRING TABLE — СТВОРЕННЯ ТАБЛИЦІ ПЛІДНИКИ / ПОТОМКИ:
# ADJUSTING THE PARENTS / OFFSPRING TABLE — НАЛАШТУВАННЯ ТАБЛИЦІ ПЛІДНИКИ / ПОТОМКИ:
# W_O_R_K_S_P_A_C_E — Р_О_Б_О_Ч_И_Й___П_Р_О_С_Т_І_Р
# GENERAL OBJECTS CREATION — СТВОРЕННЯ ГОЛОВНИХ ОБ'ЄКТІВ:
# INITIAL STATE OF THE SYSTEM — ПОЧАТКОВИЙ СТАН СИСТЕМИ:
# USERS FUNCTION CREATION — СТВОРЕННЯ КОРИСТУВАЦЬКИХ ФУНКЦІЙ:
# PARAMETERS COMBINATIONS MECHANISM IN TYPE III MODELS — МЕХАНІЗМ ПЕРЕБОРУ ЗНАЧЕНЬ ПАРАМЕТРІВ У МОДЕЛЯХ III ТИПУ:
# ADDITIONAL OBJECTS CREATION — СТВОРЕННЯ ОБ'ЄКТІВ ДЛЯ ПЕВНИХ КОМБІНАЦІЙ ПАРАМЕТРІВ:
# W_O_R_K_F_L_O_W — Р_О_Б_О_Ч_И_Й___П_Р_О_Ц_Е_С
# HIGHER LEVEL CYCLES RUNNING IN TYPES II & III MODELS — ЗАПУСК ЦИКЛІВ ВИЩОГО РІВНЯ У МОДЕЛЯХ II ТА III ТИПІВ:
# INITIAL COMPOSITION CREATION — СТВОРЕННЯ ПОЧАТКОВОЇ КОМПОЗИЦІЇ:
# MAIN WORK CYCLE — ОСНОВНИЙ РОБОЧИЙ ЦИКЛ:
# Alpha-composition of the modeled system — Альфа-склад модельованої системи:
# Beta-composition of the modeled system — Бета-склад модельованої системи:
# Gamma-composition of the modeled system — Гамма-склад модельованої системи:
# ...
# Omega-composition of the modelled system — Омега-склад модельованої системи:
# ENDING OF HIGHER LEVEL CYCLES — ЗУПИНКА ЦИКЛІВ ВИЩОГО РІВНЯ:
# F_I_N_I_S_H_I_N_G — З_А_В_Е_Р_Ш_Е_Н_Н_Я
# CREATING OBJECTS FOR RESULTS INTEGRATION — СТВОРЕННЯ ОБ'ЄКТІВ ДЛЯ ІНТЕГРАЦІЇ РЕЗУЛЬТАТІВ:
# RESULTS SAVING — ЗБЕРЕЖЕННЯ РЕЗУЛЬТАТІВ:
# RESULTS VIEWING — ПЕРЕГЛЯД РЕЗУЛЬТАТІВ (У КОНСОЛІ):
# RESULTS VISUALIZATION — ВІЗУАЛІЗАЦІЯ РЕЗУЛЬТАТІВ:
Початкові команди скрипту
На початку будь-якої моделі можуть бути корисними наступні команди
# Code page UTF-8 + Soft Wrap Long Line in the Code menu in RSudio !!!
setwd("~/data") # Робоча директорія (лише на комп'ютері Д.Ш.!!!)
rm(list = ls()) # Очищення середовища від збережених об'єктів (щоб попередні сесії роботи не заважали наступним)
В першому рядку міститься попередження, яку кодову сторінку слід використовувати під час відкриття у RStudio певного скрипту. Якщо відкрити скрипт за допомогою іншої кодової сторінки, кирилічні символи будуть відбиватися неправильно. У такому випадку слід "перевідкрити" скрипт. У RStudio для цього слід використати пункт меню File / Reopen with Encoding.
Крім того, зручно використовувати такий режим, за якого довгі рядки вписуються у екран. Це в RStudio може забезпечити пункт меню Code / Soft Wrap Long Line.
Далі корисно визначити алресу робочої директорії. Щоб зрозуміти, який адрес слід використовувати, в RStudio можна пройти шляхом Session / Set Working Directory / Coose Directory. При виконання цієї команди за допомогою меню в консолі з'явиться її коректний запис, який можна буде перенести у потрібне місце скрипта. В наведеному прикладі міститься адреса, яку використовує один з авторів даного підручника.
Видалення об'єктів, що містяться у Environment, на початку скрипту, є дуже корисним і дозволяє запобігти багатьом помилкам.
Читання та запис файлу з даними
Статистичні дослідження в R практично завжди починаються з завантаження файлу з даними; для моделювання цей етап не є обов'язковим, але також може використовуватися. В першому рядку наведеного скрипту задається робоча директорія (тут R буде шукати та створювати файли). Як приклад наведена адреса, яку використовує автор для цього курсу; звісно, у всіх інших ця адреса буде іншою (до речі, для Windows адреси побудовані інакше, ніж для Linux).
Щоб запропонувати R файл даних у вигляді \*.csv, його слід створити в електронних таблицях (Excel, Calc тощо). Якщо як десятковий роздільник використовується кома (як це буває на більшості комп'ютерів в Україні), це слід зазначити у явному вигляді.
setwd("~/!_Courses/Sex_on_R") # Робоча директорія (лише на комп'ютері Д.Ш.!!!)
Sam <- read.csv('Sample.csv', sep = ";", dec = ",") # Дані перенесені у об'єкт R
summary(Sam) # На створений об'єкт можна подивитися; ця команда виводить характеристики його стовпців
## X1 X2 X3 X4
## Min. : 2.00 Min. : 3.00 Min. : 4.00 Min. : 5.00
## 1st Qu.: 5.25 1st Qu.: 6.25 1st Qu.: 7.25 1st Qu.: 8.25
## Median : 8.50 Median : 9.50 Median :10.50 Median :11.50
## Mean : 8.50 Mean : 9.50 Mean :10.50 Mean :11.50
## 3rd Qu.:11.75 3rd Qu.:12.75 3rd Qu.:13.75 3rd Qu.:14.75
## Max. :15.00 Max. :16.00 Max. :17.00 Max. :18.00
## X5 X6
## Min. : 6.00 Min. : 7.00
## 1st Qu.: 9.25 1st Qu.:10.25
## Median :12.50 Median :13.50
## Mean :12.50 Mean :13.50
## 3rd Qu.:15.75 3rd Qu.:16.75
## Max. :19.00 Max. :20.00
save(Sam, file = "Sam.RData") # Збереження даних у форматі, що використовує R
load("Sam.RData") # Читання збереженого файлу з робочої директорії
Створення та перетворення об'єктів
Створення пустого вектору певної довжини
amount <- 10
vect <- rep(NA, amount)
vect
## [1] NA NA NA NA NA NA NA NA NA NA
Створення пустої матриці з іменованими рядками та стовпцями
rws <- c("One", "Two", "Three", "Four", "Five")
cls <- c("First", "Second", "Third", "Fourth", "Fifth", "Sixth")
mtrx <- matrix(NA, nrow = length(rws), ncol = length(cls), dimnames = list(rws, cls))
mtrx
## First Second Third Fourth Fifth Sixth
## One NA NA NA NA NA NA
## Two NA NA NA NA NA NA
## Three NA NA NA NA NA NA
## Four NA NA NA NA NA NA
## Five NA NA NA NA NA NA
Сортування рядків в матриці за значеннями певного стовпця
Для початку створимо матрицю з двох стовпців, яку у випадковому порядку заповнимо числами з певного десятка (детальніше про функцію sample() — у напівфабрикаті Формування випадкової вибірки за допомогою функції sample ()).
matr <- matrix(sample(1:10, 10), nrow = 5, ncol = 2, byrow = TRUE)
matr
## [,1] [,2]
## [1,] 4 8
## [2,] 9 2
## [3,] 3 7
## [4,] 1 6
## [5,] 5 10Атрибут byrow забезпечує заповнення матриці по рядках; без цього — по стовпцях.
Щоб відсортувати цю матрицю по значенням першого стовпця, використаємо наведену команду.
matr[order(matr[, 1]), ]
## [,1] [,2]
## [1,] 1 6
## [2,] 3 7
## [3,] 4 8
## [4,] 5 10
## [5,] 9 2До речі, можна впевнитися, що вихідна матриця не змінилася.
matr
## [,1] [,2]
## [1,] 4 8
## [2,] 9 2
## [3,] 3 7
## [4,] 1 6
## [5,] 5 10Щоб змінити початкову матрицю слід її перевизначити; у даному випадку команда узята у дужки, що забезпечує виведення її результату її виконання у консоль. Тепер матриця matr відсортована.
(matr <- matr[order(matr[, 1]), ])
## [,1] [,2]
## [1,] 1 6
## [2,] 3 7
## [3,] 4 8
## [4,] 5 10
## [5,] 9 2
Отримання параметрів певних категорій особин з з матриці символів / параметрів
При моделюванні процесів в популяціях часто доводиться окремо задавати значення певних параметрів (тривалості життя, конкурентоспроможності, виживаності, плодючості, впливу добору тощо) для певних категорій особин. Як це робити? Один з варіантів — використати мартицю символів / параметрів.
Cтворимо таку матрицю. Припустимо, у нас є 3 групи особин (One, Two, Three), що схарактеризовані чотирма параметрами A, B, C, D). Заповнимо цю матрицю якимось числами (у справжній моделі ці параметри задаються з певним сенсом…).
SP <- matrix(NA, nrow = 3, ncol = 4, dimnames = list(c("One", "Two", "Three"), c("A", "B", "C", "D")))
SP[, ] <- 1:12
SP
## A B C D
## One 1 4 7 10
## Two 2 5 8 11
## Three 3 6 9 12Тепер, коли нам треба обрати характеристики для певних особин, ми можемо брати їх з цієї матриціЮ просто використовуючі запит з назвами рядків та стовпців (змісно, беручи їх у лапки, щоб показати, що це — текстові символи). Якщо матриці заповнена числами, відповіддю на такий запит буде число.
SP["Two", "C"]
## [1] 8
Створення групи випадкових чисел
mtrx[, 1] <- runif(length(rws), 0, 10)
mtrx[, "Second"] <- runif(length(mtrx[, "Second"]), 1, 2)
mtrx
## First Second Third Fourth Fifth Sixth
## One 9.269929 1.072318 NA NA NA NA
## Two 7.516522 1.495302 NA NA NA NA
## Three 5.082234 1.143656 NA NA NA NA
## Four 1.627083 1.769866 NA NA NA NA
## Five 6.134429 1.685893 NA NA NA NA
Імітування випадкових подій
Можна використовувати й функцію floor(), і функцію trunc(). До величини, яку треба ймовірнісно округлити, додається випадкова величина, що рівномірно розподілена між 0 та 1; сума округлюється до нижчого (у разі позитивних чисел) цілого.
У наведеному прикладі середнє зі 100 округлень величини 3.3 має бути достатньо близьким до цієї величини.
ProbabRound <- rep(NA, 1000)
for (i in 1:1000) {ProbabRound[i] <- floor(3.3 + runif(1))}
mean(ProbabRound)
## [1] 3.296
Формування випадкової вибірки за допомогою функції sample ()
Функція sample(x, size, replace = FALSE, prob = NULL) може використовуватися як для генерації наборів випадкових цілих чисел, так і для вибору певної кількості об’єктів з їх сукупності. Два перші аргументи є обов’язковими: x — це діапазон, з якого здійснюється вибір, а size — розмір вибірки. Два наступних параметри є опціональними. Якщо вони не вказані, R використовує ті значення, що наведені у наведеному зразку повного запису аргументів. Так, параметр replace визначає, чи можна повторно обирати елемент, який вже був вибраний. У разі replace = FALSE після того, як обрано перший елемент, обране значення забирається з-поміж тих, що можуть бути обраними на наступному кроці. Якщо вказати replace=TRUE, команда обиратиме кожний наступний елемент з повної сукупності.
sample(1:10, 9)
## [1] 2 9 7 8 4 1 3 6 5
# sample(1:10, 11) # Тут мало б бути повідомлення про помилку
sample(1:10, 11, replace=T) # Тут усе нормально: елементи можна обирати повторно
## [1] 6 2 8 1 9 4 3 1 6 9 7
Моделювання добору за допомогою функції sample () та “вектора долі”
У попередньому прикладі наведено зразок використання функція sample(). Її можна використати для моделювання добору. Припустимо, проти особин, що перелічені у векторі Al_Pop перелічені особини, проти яких діє добір s. Величина s лежить у межах від 0 (усі виживають) до 1 (усі гинуть). Особини, на користь яких працює добір, у цьому випадку виживають усі. Звісно, неконкурентна смертність, що однаково проріджує як тих, так і інших, може бути скільки завгодно потужною.
s <- sample(2:5, 1) / 10 # Випадково обирається значення добору
s
## [1] 0.4
Al_Pop <- sample(1:100, 12) # Сукупність, яка зазнає дії добору
Al_Pop
## [1] 37 47 56 49 15 27 35 65 74 82 62 4
Fate <- c(rep(NA, s*10), rep(1, (10-s*10))) # Вектор "долі"
Fate # (один на весь скрипт; він не є випадковим)
## [1] NA NA NA NA 1 1 1 1 1 1
Lot <- sample(Fate, length(Al_Pop), replace = T) # Вектор "жереба"
Lot # (створюється окремо для кожного скорочення)
## [1] NA NA NA 1 1 NA 1 NA 1 1 1 NA
Be_Pop <- Al_Pop * Lot # Скорочена сукупність; загиблі - NA
Be_Pop
## [1] NA NA NA 49 15 NA 35 NA 74 82 62 NA
Ga_Pop <- na.omit(Be_Pop) # Остаточно скорочена сукупність
Ga_Pop
## [1] 49 15 35 74 82 62
Власна функція конкурентного скорочення чисельності (імітація на рівні груп)
Імітаційна модель може працювати з переліком груп особин з зазначенням їх чисельності (імітація на рівні груп) та з переліком особин (імітація на рівні особин). Те, який з варіантів є оптимальним, залежить від різноманіття особин. Зрозуміло, що у разі, коли різноманіття особин є невисоким, та в модельній популяції є велика кількість однакових індивідів, оптимальним є перший варіант.
Входом є три об’єкти: Capacity — це ємність середовища. Amounts — чисельності скорочуваних груп, що конкурують за Capacity, а Competitiveness — конкурентоздатність цих груп. Детальніше використаний алгоритм конкурентного скорочення розглядається тут.
Виходом є нові, скорочені чисельності груп.
Наведемо два варіанти. Перший (CompetitiveReduction0) носить детермінований характер, та таз за разом буде призводити до того ж самого результату.
CompetitiveReduction0 <- function(Capacity, Amounts, Competitiveness){
RelativCompetit <- Competitiveness/max(Competitiveness); Quoted <- RelativCompetit * Amounts
Way <- ifelse(sum(Amounts) <= Capacity, 1, ifelse(sum(Quoted) >= Capacity, 2, 3))
Reduced <- switch(Way, # Defines a formula for calculations based on value Way
Amounts, # If Way==1
round(Quoted*Capacity/sum(Quoted)), # If Way==2, & on next row — if Way==3:
round(Amounts-(Amounts-Quoted)*(sum(Amounts)-Capacity)/(sum(Amounts)-sum(Quoted))) )}Ідеології імітаційного моделювання краще відповідає варіант з ймовірнісним округленням.
CompetitiveReduction <- function(Capacity, Amounts, Competitiveness){
RelativCompetit <- Competitiveness/max(Competitiveness); Quoted <- RelativCompetit * Amounts
Way <- ifelse(sum(Amounts) <= Capacity, 1, ifelse(sum(Quoted) >= Capacity, 2, 3))
Reduced <- switch(Way, # Defines a formula for calculations based on value Way
Amounts, # If Way==1
floor(Quoted*Capacity/sum(Quoted) + runif(1)), # If Way==2, & on next row — if Way==3:
floor(Amounts-(Amounts-Quoted)*(sum(Amounts)-Capacity)/(sum(Amounts)-sum(Quoted)) + runif(1)) )}Таке скорочення чисельності задовольняє двом важливим умовам: 1) сумарна чисельність груп до скорочення знижується до величини, яка відповідає забезпеченості ресурсами; 2) чисельність кожної групи до конкурентного скорочення Amounts[i] знижується до такої чисельності після конкурентного скорочення Reduced[i], що в кожній групі частка особин, які збереглися після конкурентного скорочення, пропорційна конкурентоспроможності представників цієї групи: Competitiveness[i]/max(Competitiveness).
Після того, як функція створена, її можна використовувати для перерахунку чисельності модельної популяції. Створимо приклад. Конкурентноздатність різних груп задана в стовпці “Compet”. Зверніть увагу, що найконкурентноздатніша група має конкурентноздатність 1. У разі, якщо набір конкурентноздатностей є іншим, його можна пропорційно змінити так, щоб значення для різних груп розподілялися у діапазоні від 0 до 1.
Використаємо ймовірнісний варіант; щоб він спрацьовував однаковим чином раз за разом, використаємо команду set.seed(), яка задає ту чи іншу початкову точку (задану якимось числом) у ланцюжку подій, що призводять до генерації випадкових (насправді, псевдовипадових) чисел.
set.seed(123456)
K <- 20
rws <- c("A", "B", "C", "D", "E", "F")
cls <- c("Codes", "Compet", "s", "Al", "Be")
ModelPop <- matrix(NA, nrow = length(rws), ncol = length(cls), dimnames = list(rws, cls))
ModelPop[, "Codes"] <- 1:6
ModelPop[, "Compet"] <- c(1, 0.9, 0.1, 0.8, 0.5, 0.4)
ModelPop[, "Al"] <- c(12, 20, 15, 6, 5, 2)
ModelPop[, "Be"] <- CompetitiveReduction(K, ModelPop[, "Al"], ModelPop[, "Compet"])
ModelPop
## Codes Compet s Al Be
## A 1 1.0 NA 12 6
## B 2 0.9 NA 20 9
## C 3 0.1 NA 15 1
## D 4 0.8 NA 6 3
## E 5 0.5 NA 5 2
## F 6 0.4 NA 2 1
sum(ModelPop[, "Be"])
## [1] 22Від альфа-складу популяції ми перейшли до бета-складу. Чому бета-чисельність не чітко відповідає обмеженню ємності середовища (22 особини замість 20)? Це наслідок випадковості при реалізації алгоритму скорочення чисельності.
Скорочення чисельності популяції внаслідок добору (імітація на рівні особин)
Використаємо ту саму модельну популяцію, що й в попередньому випадку, але виконаємо імітацію скорочення чисельності не на рівні груп, а на рівні особин.
Для імітації конкуренції використаємо не величину Compet, що пропорційна шансам на виживання особини, а показник s (коефіцієнт добору). Коли s=0, добір не заважає існуванню певної форми, при s=1 він повністю її знищує.
ModelPop[, "s"] <- 1- ModelPop[, "Compet"] Створимо вектор Al_Pop, що складається з кодів кожної особини окремо.
Al_Pop <- c(rep(ModelPop[1, "Codes"], ModelPop[1, "Al"]),
rep(ModelPop[2, "Codes"], ModelPop[2, "Al"]),
rep(ModelPop[3, "Codes"], ModelPop[3, "Al"]),
rep(ModelPop[4, "Codes"], ModelPop[4, "Al"]),
rep(ModelPop[5, "Codes"], ModelPop[5, "Al"]),
rep(ModelPop[6, "Codes"], ModelPop[6, "Al"]))
Al_Pop
## [1] 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3
## [39] 3 3 3 3 3 3 3 3 3 4 4 4 4 4 4 5 5 5 5 5 6 6Тепер зробимо так, щоб ймовірність загибелі кожної особини була пропорційна s. Показаний тут варіант (з використанням циклу) є витратним з точки зору ресурсів, але більш зрозумілим.
Selection <- rep(NA, length(Al_Pop))
Randoms <- runif(length(Al_Pop), 0, 1)
for (n in 1:length(Al_Pop)) {Selection[n] <- ModelPop[which(ModelPop[, "Codes"]==Al_Pop[n]), "s"]}
Be_Pop <- Al_Pop * (floor(Randoms - Selection) + 1)
Be_Pop <- Be_Pop[-which(Be_Pop==0)]
Be_Pop
## [1] 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 4 4 4 4 4 4
## [39] 5 5 5 5
table(Be_Pop)
## Be_Pop
## 1 2 3 4 5
## 12 19 1 6 4
length(Be_Pop)
## [1] 42Чому чисельність особин не скоротилася до K? Тому що проведено лише конкурентне скорочення чисельності. Якщо чисельність бета-популяції вища за обмеження ємності середовища, слід провести наступний етап скорочення: неконкурентне скорочення.
Після того, як проведене конкурентне скорочення, ймовірність загибелі кожної особини стає однаковою. Вона має залежати від співвідношення бета-чисельності популяції та ємності середовища.
if(length(Be_Pop) > K) {
Randoms <- runif(length(Be_Pop), 0, 1)
Ga_Pop <- Be_Pop * (floor(Randoms - (length(Be_Pop)-K)/length(Be_Pop)) + 1)
Ga_Pop <- Ga_Pop[-which(Ga_Pop==0)] }
Ga_Pop
## [1] 1 1 1 1 2 2 2 2 2 2 2 2 4 4 5
table(Ga_Pop)
## Ga_Pop
## 1 2 4 5
## 4 8 2 1
length(Ga_Pop)
## [1] 15Лишилося менше особин, ніж мало залишитися. Випадковість…
Конкурентне скорочення популяції з різних форм особин
Розглянемо популяцію чисельністю N, що складається з двох форм, A та B. Зрозуміло, що NA + NB = N. Чисельність цієї популяції має обмеження K, що відповідає параметру Ферхюльста (ємності середовища, чисельності особин, для якої вистачає ресурсів). Якщо N > K, має відбутися обмеження чисельності. Якщо особини A та B відрізняються, вони можуть мати різну конкурентоспроможність.
Розглянемо приклад з певними значеннями. Припустимо, NA = 60 та NB = 40. Має відбуватися скорочення, тому що K = 80. Особини A та B відрізняються за конкурентоспроможністю: cA = 0.6 та cB = 0.45.
Initial <- c(rep("A", 60), rep("B", 40))
N_A <- sum(Initial == "A")
N_A
## [1] 60
N_B <- sum(Initial == "B")
N_B
## [1] 40
N <- length(Initial)
N
## [1] 100
K <- 80
c_A <- 0.6
c_B <- 0.45Оскільки ми маємо значення конкурентоспроможності c, ми можємо на їх підставі розрахувати значення відносної конкурентоспроможності rc: rci = ci/max(ci). У такому разі rcA = 0.75 та rcB = 1 (в популяції з іншим складом відносні конкурентоспроможності кожної з форм можуть бути іншими, адже вони залежать від складу популяції).
rc_A <- c_A / max(c_A, c_B)
rc_B <- c_B / max(c_A, c_B)
rc_A
## [1] 1
rc_B
## [1] 0.75У такому разі ймовірність збереження особини A має бути pA = K/(NA + rcB×NB). Ймовірність збереження особини B, відповідно, pB = rcB × pA.
p_A <- K / (N_A + rc_B * N_B) # Слід починати розрахунок з форми, для якої rc дорівнює 1!
p_A
## [1] 0.8888889
p_B <- rc_B * p_A
p_B
## [1] 0.6666667
reduced_N <- p_A*N_A + p_B*N_B
reduced_N
## [1] 80
reduced_N == K
## [1] TRUEМи отримали ту саму чисельність, яку мали отримати: популяцію скорочено до K, ємності середовища.
Втім, ми маємо отримати не заздалегідь визначену чисельність, яка відповідає найімовірнішому стану; імітаційне моделювання вимагає відбиття у моделі випадкових, імовірнісних процесів. Як це реалізувати?
Розглянемо два шляхи. Перший з них такий. Створимо послідовність випадкових чисел, що розподілені від 0 до 1. Будемо визначати: у разі, якщо на певній позиції стоїть елемент A, він збережеться, якщо відповідне випадкове число менше за ймовірність збереження елементів A, а у разі елемента B будемо порівнювати випадкове число з ймовірністю збереження цих елементів.
set.seed(1234567)
Reduced1 <- Initial[ (Initial == "A" & runif(N) < p_A) | (Initial == "B" & runif(N) < p_B) ]
Reduced1
## [1] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
## [20] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A"
## [39] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "B" "B"
## [58] "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B" "B"
## [77] "B" "B" "B" "B" "B"
table(Reduced1)
## Reduced1
## A B
## 55 26У разі використання випадкових чисел, що визначені командою set.seed(12345) залишилося не 80 особин, а 81. Чому? Просто пощастило!
Другий шлях скорочення такий.
Reduced2 <- sample(Initial, K, prob = ifelse(Initial == "A", p_A, p_B), replace = FALSE)
table(Reduced2)
## Reduced2
## A B
## 48 32У даному випадку залишилося саме 80 особин, і так буде за будь-яких випадкових чисел, тому що функція sample() відраховує саме K особин, а ось серед цих 80 особин випадковим чином бути більше чи менше A або B. Можна зрозуміти, що перший шлях більше відповідає сутності імітаційного моделювання.
Керування розрахунками
Перемикач у разі множинного вибору: switch()
Залежно від того, яке значення приймає певна величина (у прикладі вона названа Way), слід робити ті чи інші дії. Для цього використовується перемикач switch(). Величина Way має приймати значення натурального ряду. Якщо вона приймає значення з якогось переліку, можна зробити список можливих значень та впорядкувати його, як показано на початку прикладу.
Randoms = sample(10:99, 5)
Randoms
## [1] 27 32 63 93 56
Rando <- sort(unique(Randoms))
Rando
## [1] 27 32 56 63 93
x <- sample(Rando, 1)
x
## [1] 56
Way <- which(x == Rando)
switch(Way,
print(Rando[1]),
{print(Rando[2]); print("Second")},
{print(Rando[3]); (a <- x^2)},
print(Rando[4]),
print(Rando[5]))
## [1] 56
## [1] 3136
Перебір значень початкових параметрів
Застосовується у моделях ІІІ типу
vector_First <- c(100, 200, 300, 400)
vector_Second <- c(0.1, 0.2, 0.3, 0.4, 0.5)
Outcome <- matrix(NA, nrow = length(vector_First), ncol = length(vector_Second), dimnames = list(vector_First, vector_Second))
for (a in 1:length(vector_First)){
First <- vector_First[a]
for (b in 1:length(vector_Second)){
Second <- vector_Second[b]
Outcome[a, b] <- First + Second * 100 # Тут розташовані основні розрахунки результату
}}
Outcome
## 0.1 0.2 0.3 0.4 0.5
## 100 110 120 130 140 150
## 200 210 220 230 240 250
## 300 310 320 330 340 350
## 400 410 420 430 440 450
Виведення у консоль звітів про прогрес у розрахунках
Якщо модель вимагає тривалих розрахунків, виникає проблема невизначеності: працює вона або ні, скінчить роботу ось-ось, або через кілька тижнів? Річ у тому, що після того, як запущено скрипт моделі, протягом усього часу розрахунків на екрані комп’ютера нічого не відбувається. Користувач не впевнений: відбувається розрахунок або програма просто “зависла”? Розрахунок завершиться швидко, чи може тривати добами, чи тижнями? Від такої невпевненості допомагають засоби, що демонструють прогрес виконання завдання.
Зробимо скрипт, який може працювати довго, і застосуємо для цього “чотириповерховий” цикл. Коли показник Cons невеликий, скрипт виконується швидко, але якщо збільшити цей показник, припустимо, на порядок, кількість (і час розрахунків) збільшиться на чотири порядки. В найвищий цикл вставлено команду print() що виводить вказане значення у консоль. На вивід надішлемо конструкцію, створену програмою paste(), яка поєднує аргументи, перелічені у дужках через кому.
Cons <- 10
z <- 0
for (f in 1:Cons) {
print(paste(f, "from", Cons))
y <- 0
for (s in 1:Cons) {
x <- 0
for (t in 1:Cons) {
w <- 0
for (f in 1:Cons) {
w <- w + f}
x <- x + w}
y <- y + x}
z <- z + y}
## [1] "1 from 10"
## [1] "2 from 10"
## [1] "3 from 10"
## [1] "4 from 10"
## [1] "5 from 10"
## [1] "6 from 10"
## [1] "7 from 10"
## [1] "8 from 10"
## [1] "9 from 10"
## [1] "10 from 10"
z
## [1] 55000Можна виводити розрахунки у процентах (%, тобто частках на сотню) або у проміле (‰), частках на тисячу, адже у команду print(paste()) можна вставити необхідні розрахунки.
Елементи статистики
cor.test(mtrx[ , "First"], mtrx[ , "Second"], method ="spearman")
##
## Spearman's rank correlation rho
##
## data: mtrx[, "First"] and mtrx[, "Second"]
## S = 14, p-value = 0.6833
## alternative hypothesis: true rho is not equal to 0
## sample estimates:
## rho
## 0.3Звісно, можна вказати method = “pearson”
Візуалізація результатів
Побудова простої діаграми розсіювання (scatterplot)
plot(mtrx[, "First"], mtrx[, "Second"], main = "General scatterplot", xlab = "First axis", ylab = "Second axis")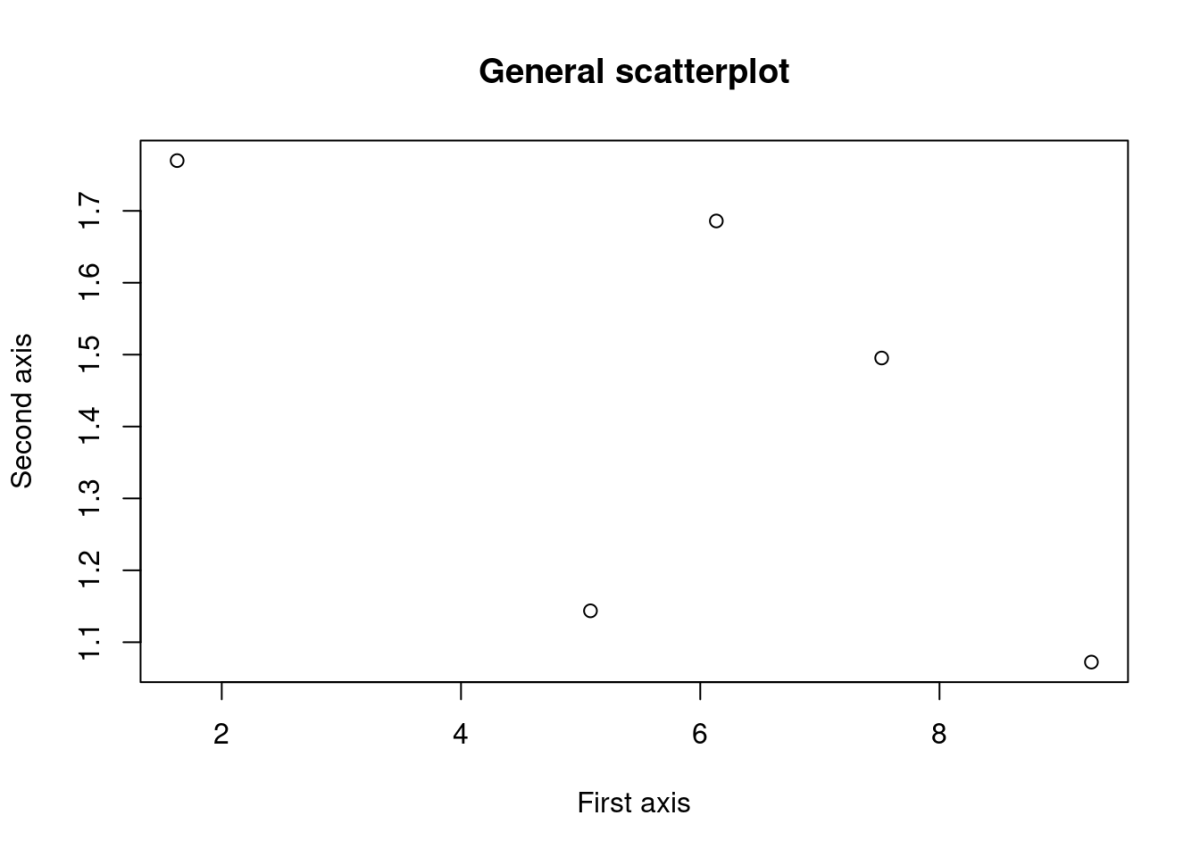
Діаграма розсіювання з лінією регресії
Перша частина цього прикладу генерує дані; у разі використання цього напівфабрикату дані будуть отримані з якогось іншого джерела. Використана залежність Second = 10 + 2×First + 0.5×First^2 + err, де err — помилка (шум). Щоб її розрахувати, використано випадкове число від 0 до 1 та множинник i×10, що робить цей шум гетероскедастичним, тобто залежним від тієї величини, до якої він додається.
First <- 1:50 # Перша змінна
Second <- rep(NA, 50) # Вектор, де буде створена друга змінна
set.seed(1234)
for(i in First) {Second[i] <- 10 + 2 * First[i] + 0.5 * First[i]^2 + i*5*runif(1)} # Значення другої змінної розраховуються за допомогою циклу; цей етап потрібний для формування даних для цього прикладу
plot(First, Second) # Побудова діаграми розсіювання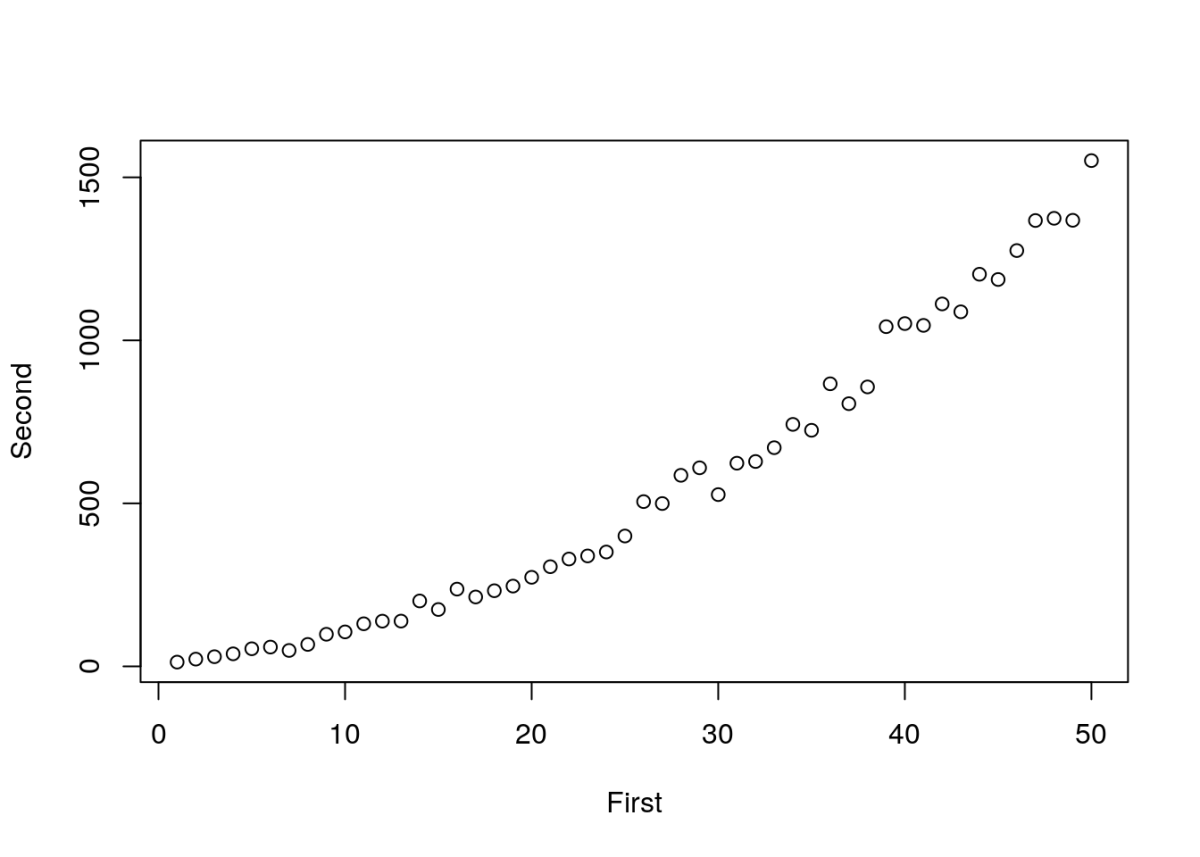
Функція lm — універсальний засіб для розрахунку регресійних залежностей; слід вказати форму, яку повинна мати залежність, що буде розрахована. Можна подивитися, що вийшло.
depend <- lm(Second ~ First + I(First^2)) # Створюється об'єкт, що містить розрахунок регресії (у даному випадку - квадратичної)
depend # В консоль виводиться отримана регресійна залежність...
##
## Call:
## lm(formula = Second ~ First + I(First^2))
##
## Coefficients:
## (Intercept) First I(First^2)
## 17.5222 2.9749 0.5332
summary(depend) #... та пов'язані з нею детальні розрахунки
##
## Call:
## lm(formula = Second ~ First + I(First^2))
##
## Residuals:
## Min 1Q Median 3Q Max
## -75.234 -19.487 -5.267 15.145 97.434
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 17.5222 16.0527 1.092 0.2806
## First 2.9749 1.4521 2.049 0.0461 *
## I(First^2) 0.5332 0.0276 19.317 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 36.33 on 47 degrees of freedom
## Multiple R-squared: 0.9938, Adjusted R-squared: 0.9936
## F-statistic: 3776 on 2 and 47 DF, p-value: < 2.2e-16Ми бачимо, що функція lm оцінила, як ми генерували вектор Second. У випадку використаних умов, що визначають вибор випадкових чисел (set.seed(1234)) оцінка залежності є такою: Second = 17.5 + 2.9×First + 0.53×First^2 + err. Зовсім непогано! Звісно, при інших значеннях set.seed() ступінь відповідності може бути іншою.
Зверніть увагу, що перша змінна квадратичного рівняння показана як Intercept.
Лишилося поєднати на діаграмі наявні дані та розраховану лінію регресії.
plot(First, Second, main = "Діаграма розсіювання з лінією регресії", # Створення діаграми розсіювання
xlab = "First", ylab = "Second")
curve(predict(depend, newdata = data.frame(First = x)), # Додавання лінії регресії; вона створюється для нового датафрейма, значення першої змінної якого відповідають тим, що були використані у основному прикладі
from = min(First), to = max(First), col = "red", lwd = 2, add = TRUE)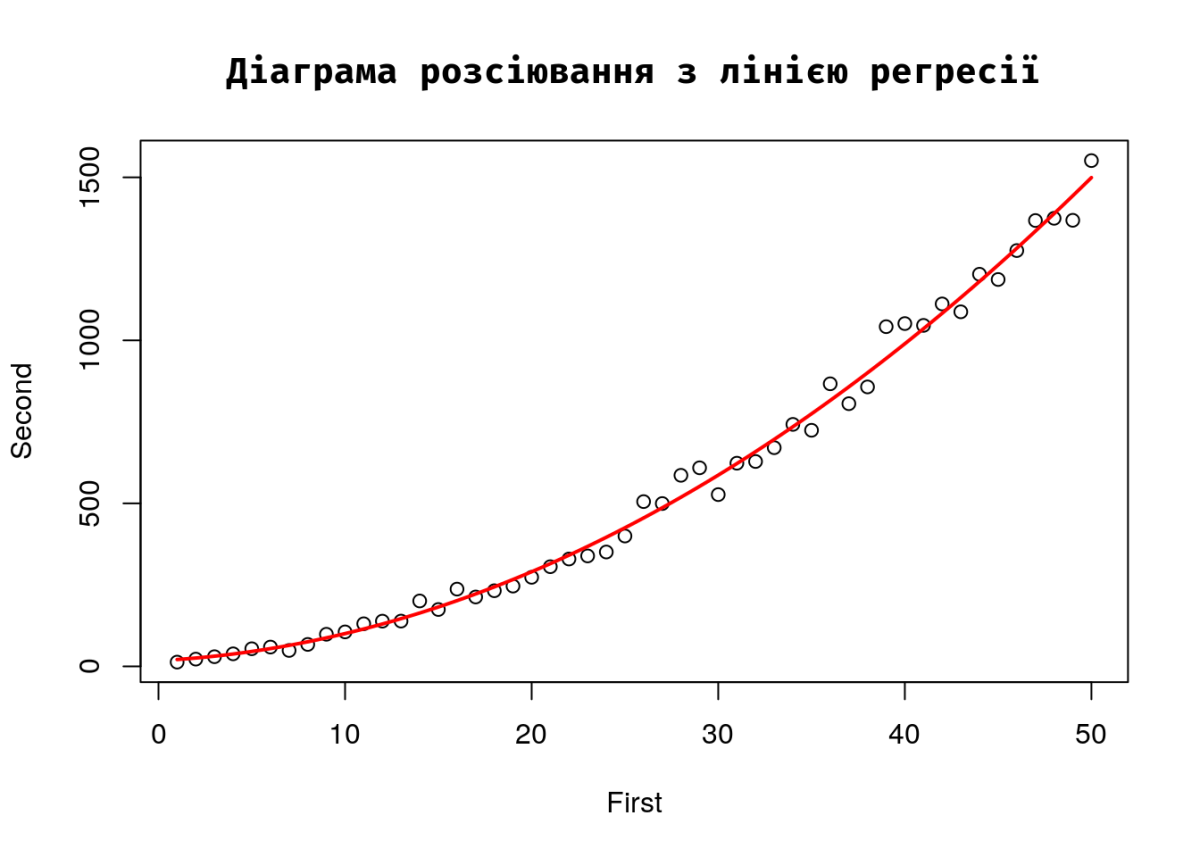
Складним для розуміння моментом є вираз newdata = data.frame(First = x) в функції predict. Це — аргумент для створеної нами моделі depend. На діаграму додаєтся лінія прогнозу, що розраховується з новоствореного набору даних за допомогою отриманого нами рівняння регресії. В цій моделі є значення First; їй слід вказати, що ці дані відповідають значенням осі x (абсцис).
Побудова лінійного графіку для трьох змінних (line chart)
Спочатку створимо матрицю з даними, які будемо візуалізувати (використання функції sample() пояснено далі).
mtr <- matrix(NA, 3, 20)
mtr[ , 1] <- sample(10:30, 3)
for (i in 2:20) {mtr[ , i] <- mtr[ , i-1] + sample(-2:2, 3)}
mtr
## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10] [,11] [,12] [,13] [,14]
## [1,] 29 27 28 28 26 24 24 24 23 22 23 23 21 22
## [2,] 10 12 14 13 13 15 17 15 17 19 19 20 19 21
## [3,] 11 10 10 8 10 11 9 8 9 9 11 10 12 11
## [,15] [,16] [,17] [,18] [,19] [,20]
## [1,] 24 26 25 24 23 21
## [2,] 20 18 19 17 18 19
## [3,] 9 9 9 10 8 8Тепер можна побудувати графік
plot(mtr[1, ], type="l", lty=2, col="red", # Перша лінія
main = "Line chart", # Заголовок
ylim = c(0, max(mtr)), # Масштаб осі ординат
xlab="First axis", ylab="Second axis") # Підписи осей
lines(mtr[2, ], type="l", lty=3, col="blue") # Друга лінія
lines(mtr[3, ], type="l", lty=4, col="green") # Третя лінія
legend(2, 10, inset=.05, title="Позначення:", c("Перша лініяі","Друга лінія", "Третя лінія"), # Легенда
lty=c(2, 3, 4), col=c("red", "blue", "green")) # Порівнювані елементи в легенді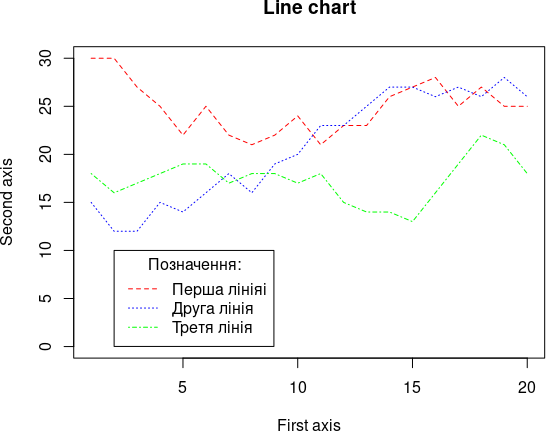
“Теплова карта” кореляції між багатьма ознаками
Спочатку заповнимо стовпці матриці ознаками, зв’язок між якими має сенс досліджувати.
mtrx[ , "Third"] <- mtrx[ , "First"] + mtrx[ , "Second"]
mtrx[ , "Fourth"] <- mtrx[ , "Third"] + runif(nrow(mtrx), 0, 1)
mtrx[ , "Fifth"] <- 2 + runif(length(mtrx[ , "Fifth"]), -1, 1)
mtrx[ , "Sixth"] <- mtrx[ , "Fifth"] + 1
mtrx
## First Second Third Fourth Fifth Sixth
## One 9.00222090 1.905020 10.907241 11.292740 1.114117 2.114117
## Two 2.79331013 1.490399 4.283709 5.099022 1.226960 2.226960
## Three 0.85959514 1.917520 2.777115 3.653694 1.684746 2.684746
## Four 0.82524304 1.340165 2.165408 2.436028 2.109354 3.109354
## Five 0.06033371 1.549691 1.610025 2.434575 2.896808 3.896808Інсталюємо (при першому запуску) та завантажимо необхідну бібліотеку
# install.packages("GGally")
library(GGally)
## Loading required package: ggplot2
## Registered S3 method overwritten by 'GGally':
## method from
## +.gg ggplot2Побудуємо “теплову карту”
ggcorr(mtrx)
Тривимірна візуалізація результатів перебору параметрів
У напівфабрикаті Перебір значень початкових параметрів згенеровано матрицю Outcome. Візуалізувати її можна таким чином
# install.packages("plot3D")
library(plot3D)
persp3D(z = Outcome, x = vector_First, y = vector_Second, theta = 330, phi = 30,
zlab = "\nРезультат", xlab = "First", ylab = "Second",
expand = 0.6, facets = FALSE, scale = TRUE, ticktype = "detailed",nticks = 5, cex.axis=0.9,
clab = "Кольорова\nшкала", colkey = list(side = 2, length = 0.5))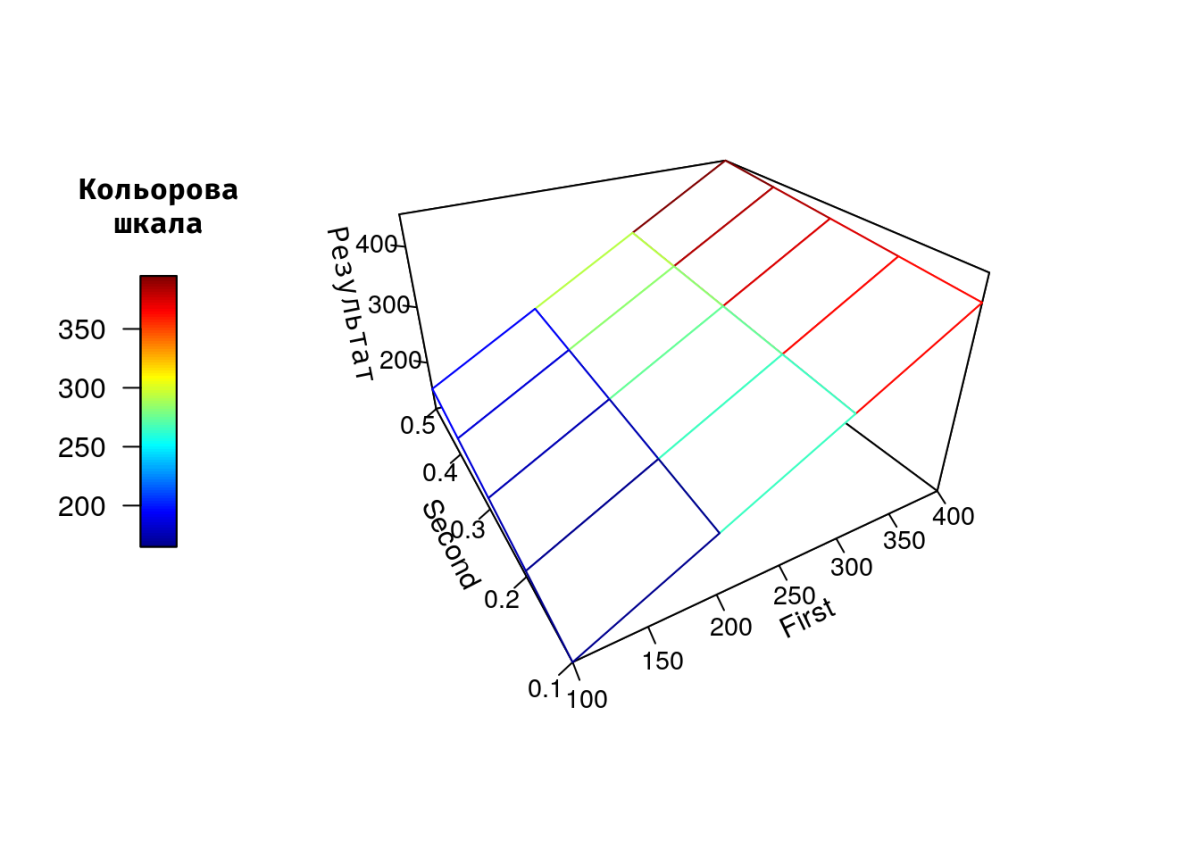
Приклади моделей
Конкуренція двох клонів в популяції, що зростає логістично
# КОНКУРЕНЦІЯ ДВОХ КЛОНІВ В ПОПУЛЯЦІЇ, ЯКА ЗРОСТАЄ ЛОГІСТИЧНО
# Клони A і B можуть відрізнятися за швидкістю розмноження та смернтістю, але перебувають під спільним обмеженням ємності середовища, що задане параметром K
# INITIAL SCRIPT COMMANDS — ПОЧАТКОВІ КОМАНДИ СКРИПТУ:
rm(list = ls()) # Очистка робочого простору перед початком
# E_N_T_R_A_N_C_E — В_Х_І_Д_Н_І___К_О_М_А_Н_Д_И
# MAIN PARAMETERS — ГОЛОВНІ ПАРАМЕТРИ:
rA <- 0.1 # Параметр Мальтуса: репродуктивний потенціал клона A
rB <- 0.1 # Параметр Мальтуса: репродуктивний потенціал клона B
dA <- 0.02 # Смертність клона A
dB <- 0.02 # Смертність клона B
K <- 100 # Параметр Ферхюльста: емність середовища, максимальна чисельність популяції, для якої достатньо ресурсів (для обох клонів)
N1A <- 20 # Початкова чисельність клона A
N1B <- 20 # Початкова чисельність клона B
# EXPERIMENTAL CONDITIONS — УМОВИ ЕКСПЕРИМЕНТУ:
set.seed(123456)
cycles <- 15000 # Тривалість експерименту (кількість кроків)
# W_O_R_K_S_P_A_C_E — Р_О_Б_О_Ч_И_Й___П_Р_О_С_Т_І_Р
# GENERAL OBJECTS CREATION — СТВОРЕННЯ ГОЛОВНИХ ОБ'ЄКТІВ:
AB <- matrix(NA, nrow = 3, ncol = cycles, dimnames = list(c("A", "B", "A+B"), 1:cycles)) # Створення пустої матриці для результатів
# W_O_R_K_F_L_O_W — Р_О_Б_О_Ч_И_Й___П_Р_О_Ц_Е_С
# INITIAL COMPOSITION CREATION — СТВОРЕННЯ ПОЧАТКОВОЇ КОМПОЗИЦІЇ:
AB["A", 1] <- N1A
AB["B", 1] <- N1B
AB["A+B", 1] <- AB["A", 1] + AB["B", 1]
# MAIN WORK CYCLE — ОСНОВНИЙ РОБОЧИЙ ЦИКЛ:
for(t in 2:cycles) {
AB["A", t] <- floor(AB["A", t-1] + rA*AB["A", t-1]*(K - AB["A+B", t-1])/K + runif(1))
AB["A", t] <- floor(AB["A", t]- dA*AB["A", t] + runif(1))
AB["B", t] <- floor(AB["B", t-1] + rB*AB["B", t-1]*(K - AB["A+B", t-1])/K + runif(1))
AB["B", t] <-floor(AB["B", t] - dB*AB["B", t] + runif(1))
AB["A+B", t] <- AB["A", t] + AB["B", t]
}
# F_I_N_I_S_H_I_N_G — З_А_В_Е_Р_Ш_Е_Н_Н_Я
# RESULTS VISUALIZATION — ВІЗУАЛІЗАЦІЯ РЕЗУЛЬТАТІВ:
plot(AB["A", ], type="l", lty=1, col="green", main="Конкуренція двох клонів",
xlab="Цикли імітації (t)", ylab="Чисельність", ylim=c(0, max(K*1.02)))
lines(AB["B", ], type="l", lty=1, col="blue")
lines(AB["A+B", ], type="l", lty=1, col="red")
abline(h=K, lty=3, col="brown4") # Лінія зі значенням K
legend(x=12500, y=50, inset=.05, title="Чисельність:", c("A", "B", "A+B", "K"),
lty=c(1, 1, 1, 3), col=c("green", "blue", "red", "brown4"))
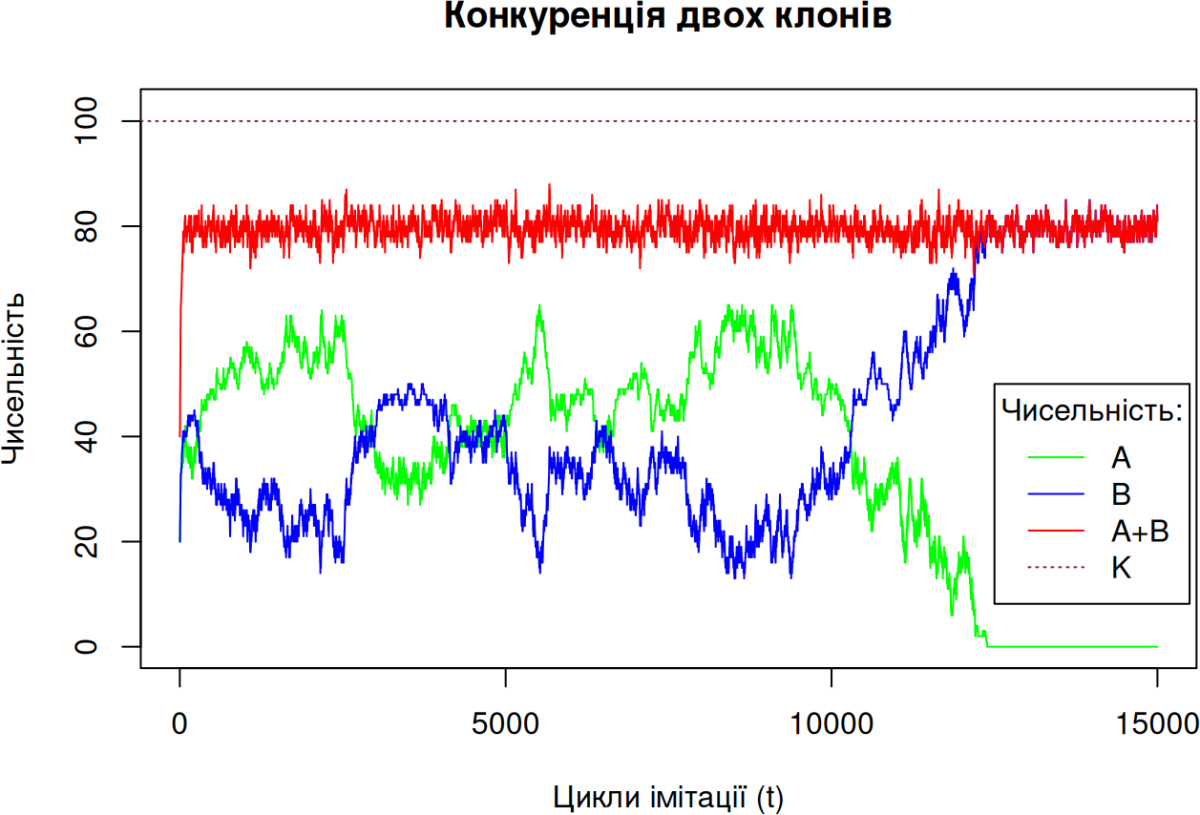
Конкуренція двох видів згідно моделі Лотки-Вольтерра (у логістичному вигляді) з лагом реакції
# МОДЕЛЬ ЛОТКИ-ВОЛЬТЕРРА НА ЛОГІСТИЧНОМУ РІВНЯННІ З ЛАГОМ (ЗАТРИМКОЮ РЕАКЦІЇ)
# Система у вигляді двох логістичних рівнянь для двох видів, у кожне з яких входить також і чисельність іншого виду; для кожного виду вплив іншого здійснюється з певною затримкою (лагом)
# INITIAL SCRIPT COMMANDS — ПОЧАТКОВІ КОМАНДИ СКРИПТУ:
rm(list = ls()) # Очистка робочого простору перед початком
# E_N_T_R_A_N_C_E — В_Х_І_Д_Н_І___К_О_М_А_Н_Д_И
# MAIN PARAMETERS — ГОЛОВНІ ПАРАМЕТРИ:
rA <- 0.5; rB <- 0.8 # Параметри Мальтуса для видів A та B
KA <- 100; KB <- 40 # Параметри Ферхюльста для видів A та B
AtoB <- -0.2; BtoA <- -0.3 # Взаємні впливи (A ⟶ B "альфа"; B ⟶ A "бета")
lagA <- 4; lagB <- 3 # Затримки реакцій популяцій A та B
# EXPERIMENTAL CONDITIONS — УМОВИ ЕКСПЕРИМЕНТУ:
cycles <- 50 # Тривалість експерименту з моделлю (кількість циклів)
# W_O_R_K_S_P_A_C_E — Р_О_Б_О_Ч_И_Й___П_Р_О_С_Т_І_Р
# GENERAL OBJECTS CREATION — СТВОРЕННЯ ГОЛОВНИХ ОБ'ЄКТІВ:
A <- rep(NA, cycles); B <- rep(NA, cycles) # Створення векторів
# INITIAL STATE OF THE SYSTEM — ПОЧАТКОВИЙ СТАН СИСТЕМИ:
A1 <- 20; B1 <- 10 # Початкові чисельность популяцій видів A та B
# W_O_R_K_F_L_O_W — Р_О_Б_О_Ч_И_Й___П_Р_О_Ц_Е_С
# INITIAL COMPOSITION CREATION — СТВОРЕННЯ ПОЧАТКОВОЇ КОМПОЗИЦІЇ:
A[1] <- A1; B[1] <- B1 # В векторах задаються початкові чисельності
# MAIN WORK CYCLE — ОСНОВНИЙ РОБОЧИЙ ЦИКЛ:
for(t in 2:cycles) {
if (t <= lagA) A[t] = A[t-1] + rA*A[t-1] * ( KA - A[t-1] ) / KA else
A[t] = A[t-1] + rA*A[t-1] * ( KA - A[t-lagA] + BtoA*B[t-lagA] ) / KA
if (t <= lagB) B[t] = B[t-1] + rB*B[t-1] * ( KB - B[t-1] ) / KB else
B[t] = B[t-1] + rB*B[t-1] * ( KB - B[t-lagB] + AtoB*A[t-lagB] ) / KB
if (A[t] <= 0 | B[t] <= 0) {A[t] <- 0; B[t] <- 0; break} }
# F_I_N_I_S_H_I_N_G — З_А_В_Е_Р_Ш_Е_Н_Н_Я
# RESULTS VISUALIZATION — ВІЗУАЛІЗАЦІЯ РЕЗУЛЬТАТІВ:
plot(A, type="l", lty=1, col="green", main="Модель Лотки-Вольтерра на логістичному \nрівнянні з лагом (затримкою реакції)",
xlab="Цикли імітації (t)", ylab="Чисельність (A, B)",
ylim=c(0, max(A[], B[])))
lines(B, type="l", lty=1, col="red")
legend(x=42, y=100, inset=.05, title="Чисельність:", c("A", "B"),
lty=c(1, 1), col=c("green", "red"))
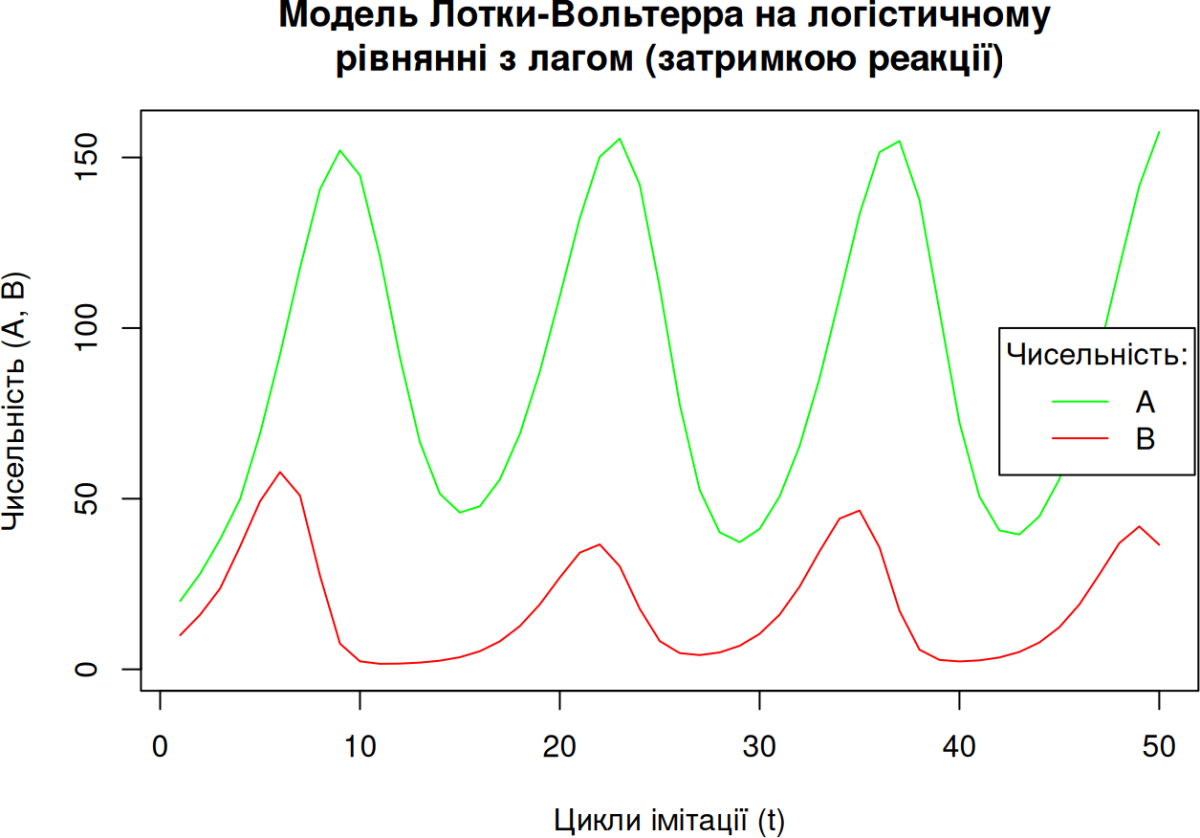
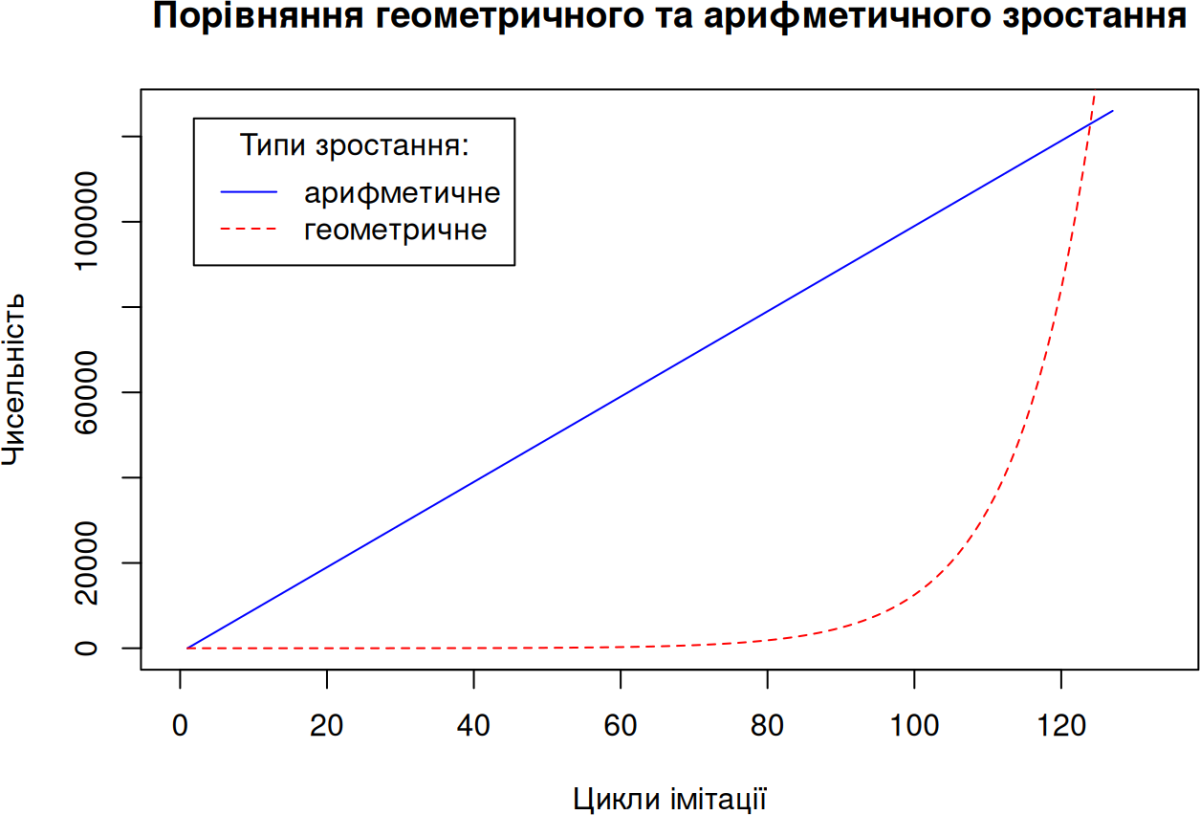
Порівняння (і “перегони”) арифметичного та геометричного зростання
# "ПЕРЕГОНИ" АРИФМЕТИЧНОГО ТА ГЕОМЕТРИЧНОГО ЗРОСТАННЯ
# INITIAL SCRIPT COMMANDS — ПОЧАТКОВІ КОМАНДИ СКРИПТУ:
N1 <- 1 # Початкова чисельність популяції (однакова для обох прогресій)
rm(list = ls()) # Очистка Environment
# E_N_T_R_A_N_C_E — В_Х_І_Д_Н_І___К_О_М_А_Н_Д_И
# MAIN PARAMETERS — ГОЛОВНІ ПАРАМЕТРИ:
N1 <- 1 # Початкова чисельність популяції (однакова для обох прогресій)
a <- 1000 # Доданок арифметичної прогресії. Показує, яка величина додається до кожного попереднього значення арифметичної прогресії
q <- 1.1 # Знаменник геометричної прогресії. Показує, на яку величину множиться кожне попереднє значення геометричної прогресії
# EXPERIMENTAL CONDITIONS — УМОВИ ЕКСПЕРИМЕНТУ:
cycles <- 1000 # Тривалість експерименту (максимальна кількість кроків))
# W_O_R_K_S_P_A_C_E — Р_О_Б_О_Ч_И_Й___П_Р_О_С_Т_І_Р
# GENERAL OBJECTS CREATION — СТВОРЕННЯ ГОЛОВНИХ ОБ'ЄКТІВ:
arithm <- rep(NA, cycles) # Створення пустого вектора для запису арифметичної прогресії
geom <- rep(NA, cycles) # Створення пустого вектора для запису геометричної прогресії
# INITIAL STATE OF THE SYSTEM — ПОЧАТКОВИЙ СТАН СИСТЕМИ:
arithm[1] <- N1 # Перенесення першого значення арифметичної прогресії
geom[1] <- N1 # Перенесення першого значення геометричної прогресії
# W_O_R_K_F_L_O_W — Р_О_Б_О_Ч_И_Й___П_Р_О_Ц_Е_С
for(t in 2:cycles) { # Цикл, що перебирає кроки імітації
arithm[t] <- arithm[t-1] + a # Добудова обох прогресій
geom[t] <- geom[t-1] * q
if (t>5) if(geom[t-3] > arithm[t-3]) break # Перевірка, чи не перегнала геометрична прогресія аріфметичну (три кроки тому, щоб результат перемоги потрапив на діаграму)
}
# F_I_N_I_S_H_I_N_G — З_А_В_Е_Р_Ш_Е_Н_Н_Я
# RESULTS VISUALIZATION — ВІЗУАЛІЗАЦІЯ РЕЗУЛЬТАТІВ:
plot(arithm, xlim=c(0, t*1.05), type="l", lty=1, col="blue",
main="Порівняння геометричного та арифметичного зростання",
xlab="Цикли імітації", ylab="Чисельність")
lines(geom, type="l", , lty=2, col="red")
legend("topleft", inset=.05, title="Типи зростання:", c("арифметичне", "геометричне"), lty=c(1, 2), col=c("blue", "red"))